





I. INTRODUCTION
A video surveillance system [1-13] is composed of video acquisition devices, data storage, and the system of data processing. Earlier video surveillance systems consisted of simple video acquisition. Recently, a video surveillance system has become a sophisticated automated system based on intelligent video analysis algorithms [13]. This system can be applied to various applications such as traffic control, accident prediction, crime prevention, motion detection, and homeland security [1]. However, a video surveillance system requires a large amount of storage. And it is inefficient to increase memory capacity continuously and take a large bandwidth when it is transmitted. Therefore, video compression technology is an effective solution to resolve the problem of restricted storage [14].
Following the successful standardization of advanced video coding (H.264/AVC) [15] and high-efficiency video coding (H.265/HEVC) [12], the joint video exports team (JVET) of ITU-T Video Coding Experts Group (VCEG) and ISO/IEC Moving Picture Experts Group (MPEG) has been finalized the Versatile Video Coding (VVC) [16] standard in July 2020. Designed with the intention of achieving a substantial reduction in bit rate compared to HEVC while maintaining the same level of visual quality, the VVC aims to provide improved compression efficiency. This standard is expected to be utilized in a variety of applications, including 8 K and higher resolution videos, game videos, screen content videos, 360-degree videos, high dynamic range (HDR) content, and adaptive resolution videos.
However, achieving such compression improvements requires high complexity, and for future standards beyond VVC, the development of new approaches and technologies will be necessary. Inspired by the success of the neural network-based approaches in the field of computer vision [17-18], neural network-based research has also started to emerge in video coding. Recently, various neural network-based coding techniques have been explored and validated through the exploration experiment (EE) of the JVET neural network-based video coding (NNVC) [19].
Research on in-loop filtering and post-filtering has been conducted actively and extensively. On the other hand, a few techniques related to prediction process have been proposed. The essence of video coding lies in eliminating the redundancy of signals. Intra and inter prediction processes generate prediction block utilizing spatial signals around the current coding unit (CU) within a frame and temporal signals in previous and/or future neighboring frames, respectively. Therefore, the prediction process, which makes the most significant contribution to redundancy removal, has a substantial impact on the overall compression efficiency.
Especially, when it comes to video data, utilizing the similarity between frames is crucial. Therefore, improving the performance of the inter prediction process can greatly enhance the overall compression efficiency. The existing deep learning-based methods can be divided into two categories: enhancement of prediction block [2,11,20] and generation of bi-prediction block [10,21]. To enhance the uni-prediction module, the prediction block can be improved using neural network.
For the bi-prediction module, the neural network-based fusion of two blocks can be employed to generate a bi-prediction block, or the existing bi-prediction block can be enhanced applying a similar approach as uni-prediction. However, despite the importance of both generating and improving prediction blocks, existing research have enhanced the inter prediction process by focusing on one of these aspects. In this paper, we propose the convolutional neural network (CNN)-based generation and enhancement method for inter prediction (GEIP) in VVC.
The proposed method utilizes an attention mechanism to create the fused feature of two prediction signals in generation model and the selfattended feature of a prediction signal in enhance model. Different from the existing deep learning-based studies, the proposed framework contains both of the enhancement of uni-prediction block and the generation of bi-prediction block, allowing for maximizing the performance of inter prediction.
In the proposed method, the enhancement network is not applied to bi-prediction block where the generation network is employed to avoid the over-filtering problem. The rest of this paper is organized as follows. In Section 2, we describe the related works. In Section 3, we present the details of the proposed method. The experimental results are shown in Section 4. Finally, Section 5 makes the concluding remarks for this paper.
II. RELATED WORKS
In VVC, several novel techniques have been proposed to enhance the inter-picture prediction features beyond HEVC [25]. In addition to traditional motion vector prediction (MVP) methods in HEVC, two novel types of MVP were introduced in VVC: history-based MVP (HMVP) and pair-wise average MVP (PAMVP).
Furthermore, the VVC has adopted three additional merge modes: merge mode with motion vector differences (MMVD), geometric partitioning mode (GPM), and combined inter and intra prediction (CIIP). The affine motion compensation (AMC) was newly applied beyond the translation motion model-based motion compensation. The weighted prediction (WP) is used to compensate for the inter prediction signal and improve coding efficiency. The WP in VVC signals the weight and offset for each reference picture and compensates for each block. In the VVC standard, two new techniques were introduced for weighted bi-prediction at the coding unit (CU) level. The first method, called bi-prediction with CU-level weight (BCW), allows for weighted prediction at the CU level. The second method, known as refinement with bi-directional optical flow (BDOF), utilizes bi-directional optical flow for further enhancement.
With the successful application of deep learning in various computer vision tasks, numerous research leveraging deep learning techniques have emerged in the field of video coding. To generate the bi-prediction block in HEVC, Zhao et al. [21] introduced a CNN-based approach that employed a patch-to-patch inference strategy. Similarly, Mao and Yu [10] proposed a CNN-based bi-prediction method called STCNN, which leveraged spatial neighboring regions and temporal display orders as additional inputs to improve the accuracy of prediction.
These methods aim to substitute the averaging bi-prediction approach in HEVC standard.
For enhancement of the uni-prediction block in HEVC, Huo et al. [2] and Wang et al. [20] proposed the CNN based motion compensation refinement (CNNMCR) and the neural network-based inter prediction (NNIP), respectively. The objective of these methods is to enhance the prediction blocks generated from the conventional standard prediction approaches.
Recently, Merkle et al. [11] proposed a CNN-based method to enhance the motion compensated prediction signal of the inter prediction block by integrating spatial and temporal reference samples. Despite these attempts to improve the inter prediction, a framework that combines both the neural network-based generation and enhancement of prediction block has not been introduced. Both aspects are crucial in inter prediction, and the proposed framework maximizes the improvement of inter prediction performance. Bao et al. presented the joint reference frame synthesis (RFS) and post-processing filter enhancement (PFE) for Versatile Video Coding (VVC), aiming to explore the combination of different neural network-based video coding (NNVC) tools to better utilize the hierarchical bi-direc-tional coding structure of VVC [23]. Both RFS and PFE utilized the Space-Time Enhancement Network (STENet), which received two input frames with artifacts and produced two enhanced frames with suppressed artifacts, along with an intermediate synthesized frame. Also, Merkle et al. have suggested a scheme for improving the prediction signal of inter blocks with a residual CNN that incorporates spatial and temporal reference samples [24]. They introduced an additional signal plane with constrained spatial reference samples which enabled decoupling the network from the intra decoding loop.
Unlike the aforementioned methods, the proposed approach implements deep learning technique to calculate an optimal reference frame through generation or synthesis for bidirectional inter-frame prediction. Additionally, it utilizes an attention-based architecture to extract optimal features.
III. METHODOLOGY
In this section, the proposed CNN-based generation and enhancement method for inter prediction (GEIP) is presented. It begins by describing the architecture of the proposed networks. Then, it provides an overview of how the proposed networks are integrated into the VVC framework.
The structure of the generation and enhancement networks in the proposed CNN-based inter prediction method is illustrated in Fig. 1. The proposed networks are designed utilizing the attention-based bi-prediction network (ABPN) [25] as a foundation. The proposed generation and enhancement networks share the same architecture as shown in Fig. 1. For the generation network, given two input reference prediction blocks IP0 and IP1, the goal of the network is to generate the bi-prediction block. In the uni-prediction, we apply the enhancement network to the traditional uni-prediction block.
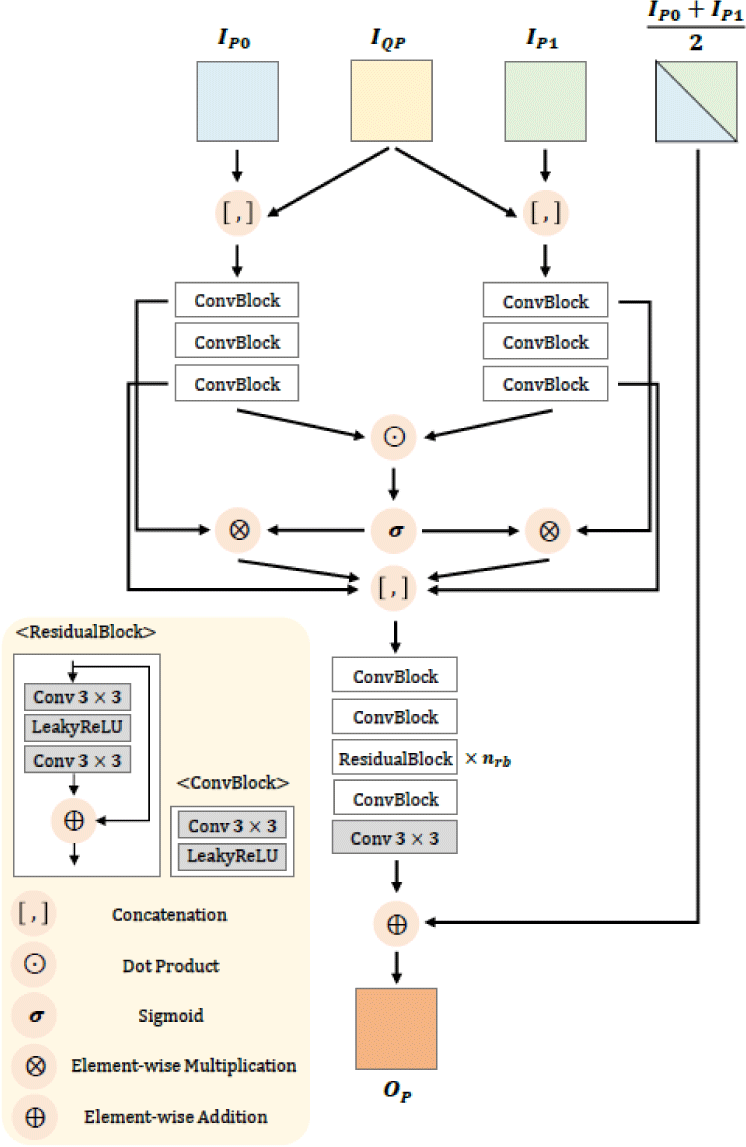
Since uni-prediction block is obtained by using only one temporal reference data, IP0 and IP1 are identical. In addition, the normalized slice quantization parameter (QP) map IQP is utilized as an input to train and apply the same model for all QP values. Each of the two concatenated prediction inputs with QP map are fed into three ConvBlock to increase the feature dimensionality. In the proposed networks, the ConvBlock consists of 2D CNN layer and the leaky rectifier linear unit (LeakyReLU). The attention map between two input features is computed using the dot product and sigmoid activation function. Let FiP0 and FiP1 denote the output feature maps of the i-th ConvBlock for IP0 and IP1, respectively. The attended features are computed as follows:
where ⊙, σ, ⊗, AFP0, and AFP1 denote the dot product,
the sigmoid activation function, the element-wise multipli-cation, the attended features for IP0 and IP1, respectively.
Therefore, the attended features represent the fused feature between two prediction blocks and the self-attended feature of a prediction block in the generation and en-hancement networks, respectively. In other words, same structure of attention module can be applied to different purpose in the proposed method.
The proposed method is integrated into the motion compensation in VVC. Based on the experimental results demonstrated in ABPN [25], the proposed networks are ap-plied only to CUs with sizes 128×128, 64×64, and 32×32.
Fig. 2 presents the flow-chart of the CNN-based generation and enhancement method for inter prediction (GEIP). First, uni-prediction process is performed for each reference picture.
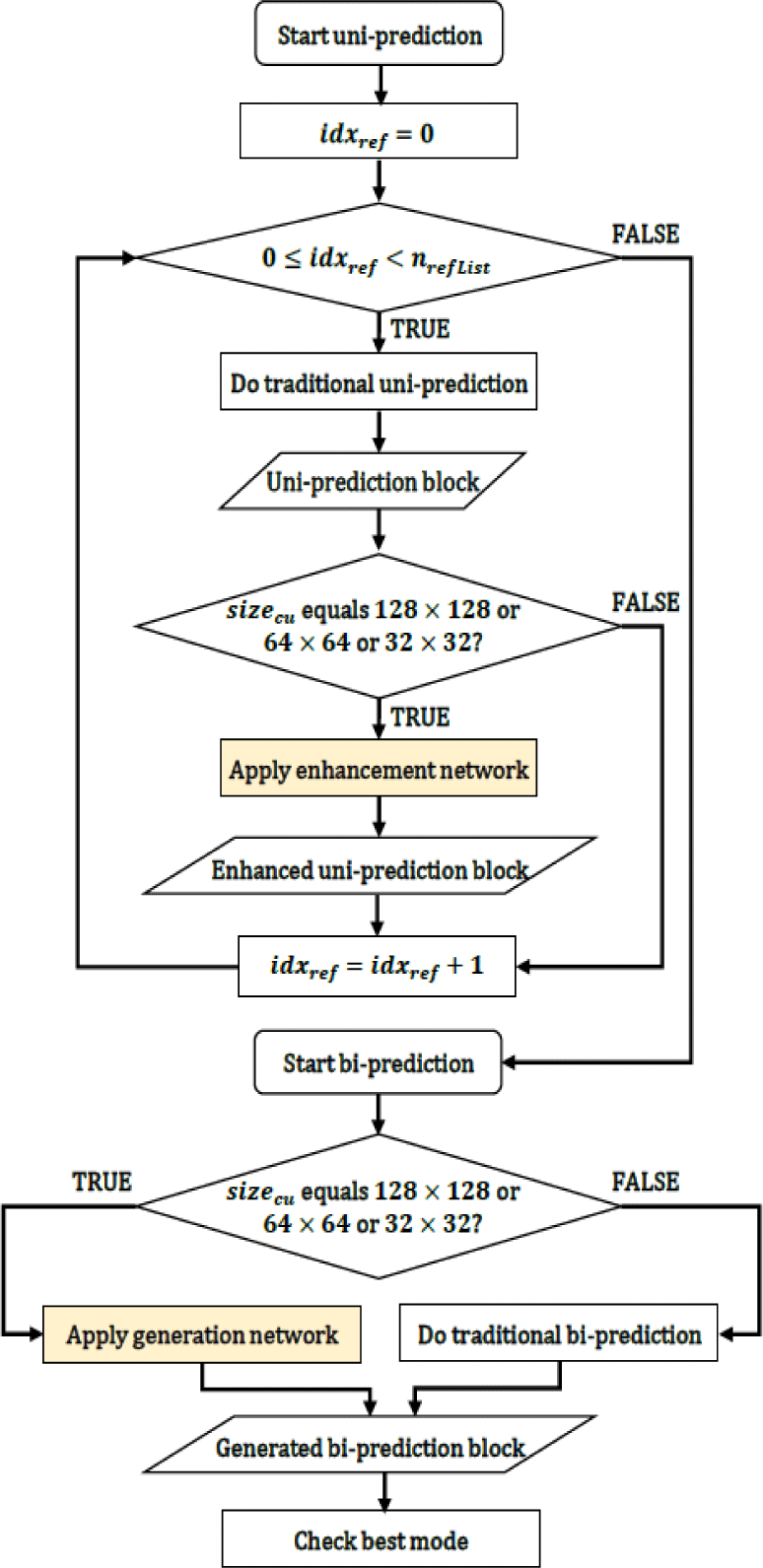
In Fig. 2, idxref , nrefList, and sizecu denote the current index of reference picture, the number of reference picture list, and the size of CU, respectively. Therefore, the ‘Uni-prediction block’ in Fig. 2 indicates the optimal uni-prediction block of traditional video coding at the current index of reference picture. The enhancement network is applied to the prediction block obtained from the traditional uni-prediction process. In other words, we can change the existing uni-prediction block into the ‘Enhanced uni-prediction block’ by the proposed method.
Second, the proposed generation network replaces the traditional bi-prediction modules for three types of block. Therefore, the traditional bi-prediction methods in VTM such as the averaging mode, BCW, BDOF, WP are not performed if the proposed method is applied to the current CU. At this time, the decoder-side motion vector refinement (DMVR) can be adopted together with the proposed method.
Different from existing studies, the proposed framework encompasses both the enhancement of uni-prediction blocks and the generation of bi-prediction blocks, maximizing inter prediction performance. Furthermore, the proposed scheme has an advantage that it does not require additional flag bits. To avoid over-filtering issues, the enhancement network is not applied to the bi-prediction block where the generation network is employed.
IV. EXPERIMENT RESULTS
We utilize the BVI-DVC sequence dataset [9] to generate the training dataset. The BVI-DVC dataset is the JVET common test conditions (CTC) training data for NNVC [4]. It contains 200 sequences, which are structured into four different resolutions. The VTM-11.0 NNVC-1.0 reference software is employed to compress the sequences with random access (RA) configuration using five QPs={22, 27, 32, 37, 42}. In decoding phase, the prediction blocks for three CU sizes 128×128, 64×64, and 32×32 are extracted as the inputs of the proposed networks. The ground-truth (GT) blocks are cropped from raw video frames. In order to train and apply a single model regardless of the QP values or CU sizes for each generation and enhancement models, we utilize the normalized slice QP map as an input and the copy and paste up-sampling technique. This approach involves copying and pasting the existing input block within a 128×128 patch to utilize all three block types together for training. The number of training data for generation network is 3,828,550, and for enhancement network, it is 3,585,057. In addition, we utilize the random horizontal flip and 90° rotation augmentation methods. We used the Adam optimizer [3] and the cosine annealing scheme [6]. The learning rate was set to 4×10−4. And the size of mini-batch and the number of iterations were set to 128 and 600 K. The proposed ABPN was implemented in PyTorch on a PC with an Intel(R) Xeon(R) Gold 6256 CPU@3.60 GHz and a NVIDIA Quadro RTX 8000-48 GB GPU. The proposed network consists of 64 features for each CNN layer except the last layer. And the number of residual block nrb was set to 10. The proposed network has 1,110,657 parameters.
The proposed method has been integrated into VTM-11.0 NNVC-1.0 reference software. The PyTorch library 1.7.1 is adopted to implement the proposed method. We follow the JVET CTC for neural network-based video coding technology [4] and utilize the random access (RA) configuration under five QPs={22, 27, 32, 37, 42}. In the experiments, we conducted 1 group of picture (GOP) test for class B and 1 second test for classes C and D on VVC CTC sequences due to the lack of time for experiments.
The results of the BD-rate reduction and encoding/ decoding computational complexity compared to VTM-11.0 NNVC-1.0 anchor on RA for the Y component are reported in Table 1. It is observed that 1.12% BD-rate saving can be achieved on average.
In particular, the proposed method achieves up to 7.06% BD-rate reduction for BQSquare. As a result, the proposed method offers the potential to significantly improve inter prediction performance in video coding. Generally, the VVC standard considers only the format of the coded bitstream, syntax, and the operation of the decoder.
Therefore, the crucial measure for the computational complexity is the decoding running time. The proposed method showed 1,467% of decoding time on average under RA. Several recent JVET standard input documents for CNN-based inter prediction technology, JVETY0090 [7], JVET-Z0074 [8], and JVET-AA0082 [5], show 23,785%, 28,226%, and 175,647% of decoding time on average of classes B, C, and D under RA compared to VTM-11.0 NNVC-1.0 anchor. It can be seen that the proposed method is superior to the recent CNN-based inter prediction methods in terms of the computational complexity. Fig. 3 presents the qualitative results on BQSquare and PartyScene. It can be observed that the proposed method can remove the noise on the table by comparing Fig. 3(a) and Fig. 3(b). Therefore, we can verify that the proposed method can reduce the compression artifacts.

As shown in Figs 3(c) and (d) the proposed GEIP more accurately restores the texture of clothes of moving person. It means that the proposed method recovers more clear edge details.
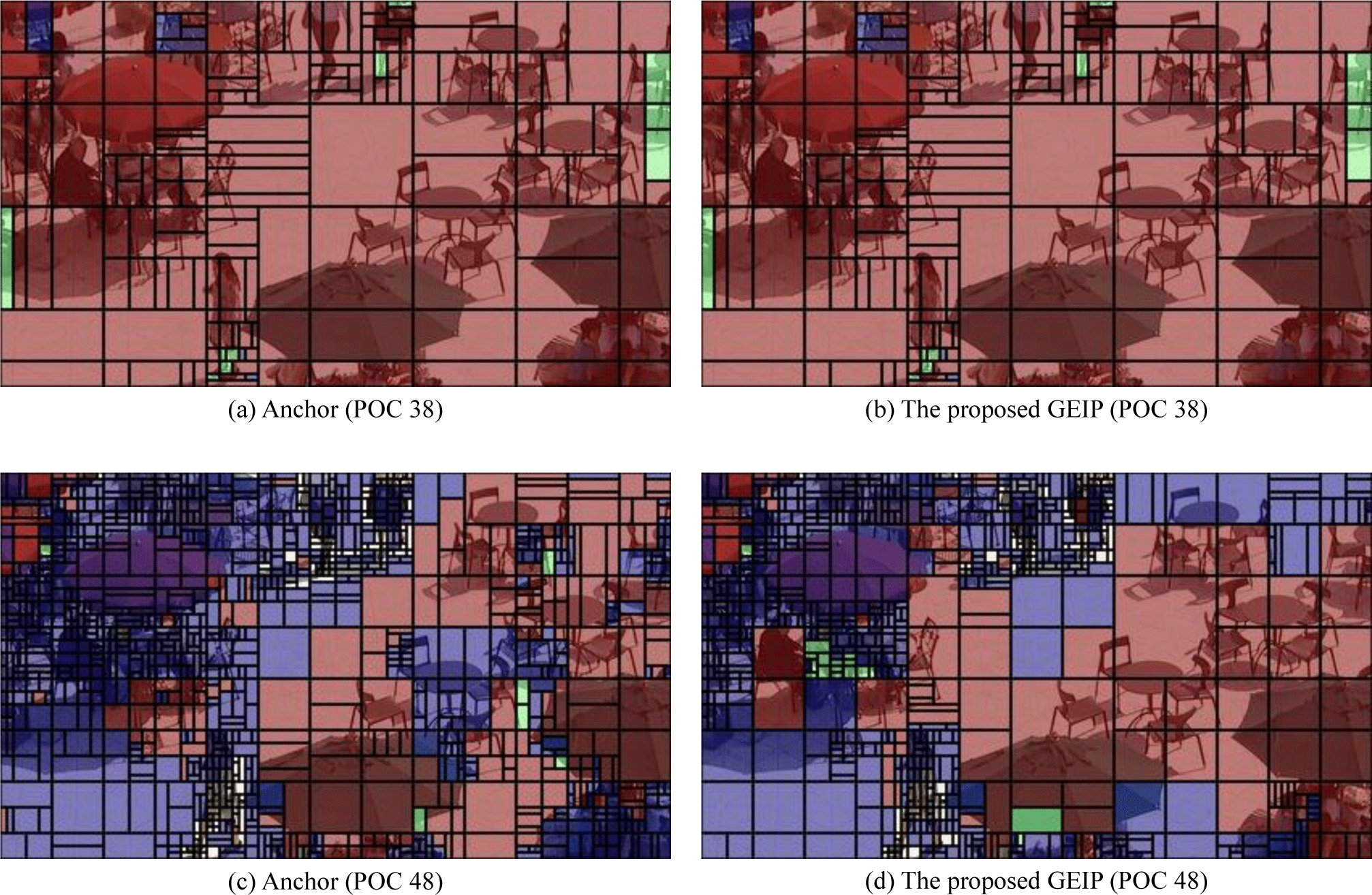
Fig. 4 shows the visualization results of the InterDir flag for CUs in BQSquare sequence. For this figure, we used two frames (POC 38 and 48) under QP 27 and RA configuration. The blue, green, and red blocks indicate L0 unidi-rectional, L1 uni-directional, and bi-directional InterDir flags, respectively. On the whole, the portion of three CU sizes 128×128, 64×64, and 32×32 is increased compared to VTM anchor. Since the small size of blocks can be merged into the large size of blocks, coding bits for a CU can be reduced.
V. CONCLUSION
In this paper, we have proposed a convolutional neural network (CNN)-based generation and enhancement method for inter prediction in the Versatile Video Coding (VVC) standard. By utilizing an attention mechanism, the proposed method achieves both the enhancement of uni-prediction blocks and the generation of bi-prediction blocks, maximizing the performance of inter prediction. Different from existing research, the proposed framework addressed both aspects of generating and improving prediction blocks, offering a comprehensive approach for inter prediction. The experimental results demonstrated the effectiveness of the proposed method in improving compression efficiency. The proposed approach achieved up to 7.06% BD-rate saving for the Y component under RA compared with the VTM-11.0 NNVC-1.0 anchor. As a result, the proposed method can contribute to the advancement of neural network-based video coding techniques. In future work, the computational complexity of the proposed inter prediction scheme can be reduced by redesigning the algorithm of integration.





