





I. INTRODUCTION
In the real world, humans often have the ability to discover and locate new objects that they have never seen before. This capability enables humans to adapt and learn in environments where they encounter new things. However, current state-of-the-art general object detection models do not perform well in recognizing and locating these new categories of objects. The underlying reason is that these models are designed based on a closed-world assumption. Simply put, their primary task is to identify and locate objects that have been annotated, while unannotated areas are defaulted to be treated as background by the model. Therefore, These models often struggle to recognize and locate objects from new categories [1].
The open world object localization task is dedicated to identifying and localizing all potential object regions in an image, encompassing both known and unknown object cat-egories. In this task, generating high-quality object proposals is crucial, serving as the foundation for the model to learn in an open world environment.
To address this task, there are currently two categories of methods. The first category focuses on introducing samples of unknown categories into model training. By learning the characteristics of these unknown samples, the model can enhance its ability to locate and recognize unknown objects. The key to this approach lies in improving the model’s generalization performance, enabling it to better adapt to various unknown situations that may arise in the real world. For instance, ORE [2] and OSODD [3] utilize unknown-aware RPNs to generate pseudo-labels for unknown objects, while Zhao [4] employs non-parametric selective search to improve the quality of pseudo labels. The second category of methods focuses on enhancing the model’s capacity to extract features from object candidate regions or improving the quality of training samples. These methods mine common object features from existing training data, enabling the model to generate more accurate object proposals in an open world environment. The core of this approach is to enhance the model’s learning ability, allowing it to more accurately capture the essential characteristics of objects. For example, Kim designed the OLN network [5] to mine object features by learning the associations between object candidate regions and ground truth boxes in terms of location and shape. Additionally, some work combines features extracted by the backbone network and those from regression branches in convolutional layers, enabling the model to mine higher-quality object features.
Existing open world object localization methods, whether through introducing unknown category samples, enhancing the model’s ability to mine features from object candidate regions, or improving the quality of training samples, primarily focus on enhancing the model’s ability to learn from high-quality positive samples. This tendency may lead to the model mistakenly selecting negative samples during the sampling process, as illustrated in Fig. 1, where background samples may contain highly object-like samples. Additionally, general object detection models perform poorly in open environments mainly because they encounter more unknown category samples during the classification phase, increasing the risk of unknown objects being misclassified as known categories.

Addressing the aforementioned issues, we propose a method. This method aims to enhance the localization accuracy of the model for unknown category objects without introducing samples from unknown categories. It achieves this by strengthening the model’s ability to learn from negative and low-quality samples. Additionally, this method can also improve the classification accuracy of the model for known categories. Specifically, aiming at the problems existing in open world object localization tasks, especially the challenges faced by the model when processing samples with weak object features and background samples, as well as the impact of unknown category samples on general object detection models, this paper proposes the following improvements based on the FCOS [6] baseline network:
-
To address the difficulty of effectively learning from low-quality samples with weak object features in open world localization tasks, we introduce a negative sample generation module to produce such samples for the localization task. This ensures that the model can encounter and learn from samples of varying quality, rather than being limited to high-quality object samples.
-
To address the potential issue of unlabeled strong object-like samples in background sampling for object detection tasks, we utilize the negative sample generation module to provide the model with purer background samples, reducing the risk of interference from mislabeled background samples during training.
-
To address the problem that the model cannot effectively distinguish between known and unknown category samples during the classification stage of object detection, we introduce an offline Out-Of-Distribution (OOD) detector. Before the model performs classification, it screens the input samples to filter out unknown category samples, thereby reducing their number in the classification stage.
II. RELATED WORK
This section will introduce the development of open world object detection [7-12]. Unlike general object detection, open world object detection focuses on identifying and processing objects of unknown categories in open and uncertain environments. Open world learning mimics human learning abilities, enabling models to gradually incorporate newly discovered categories into the set of known categories, thereby recognizing and detecting unknown objects. Early research [5] primarily focused on generating candidate regions for new objects without involving category recognition and classification, which is a crucial prerequisite for open world object detection. Against this background, ORE [2] was the first to propose an open world object detection framework, which labels unknown categories as “unknown” and learns from them after obtaining labels, allowing the model to flexibly adapt to new categories. Next, we will separately introduce the research status of open set object recognition and detection, open world object recognition and detection, as well as open world object localization, which is closely related to this paper.
Open set object recognition and detection is a significant research direction in the field of computer vision, aiming to address the diversity and uncertainty of object categories in dynamic and complex environments. Research in this area is crucial for enhancing the robustness and adaptability of models, especially in practical application scenarios such as autonomous driving and intelligent surveillance.
Open set object recognition requires the model to accurately identify known objects and correctly label unknown objects after being trained solely on samples of known classes. Scheirer et al. [13] developed an open set classifier under the one-vs-rest framework, improving the classification performance for known samples and reducing the risk of misidentifying unknown samples. The OpenMax [14] classifier further advanced this field by recognizing unknown classes in deep feature spaces, enhancing the accuracy of discrimination against unknown categories. Liu et al. [15] introduced the long-tail recognition setting and developed a metric learning framework that effectively identifies unseen categories as unknown. Other approaches, such as out-of-distribution sample detection [16] and novel class recognition [17], also enhance the accuracy of open set recognition. The introduction of self-supervised learning [18] and unsupervised learning [19] has brought new perspectives to this field.
Open set object detection is more complex, as it requires the model to precisely locate unknown objects during training and address the challenge of distinguishing between known and unknown objects. Dhamija et al. [1] were the first to propose the open set object detection protocol, guiding subsequent research efforts. Miller et al. [20] enhanced the accuracy of object detection by extracting uncertainty information from labels. Subsequent studies utilized spatial and semantic uncertainty metrics of object detectors to exclude unknown objects [21]. Miller et al. [22] also found that affinity clustering combinations can improve classification, uncertainty estimation, and object detection performance. However, these methods lack adaptability in dynamic environments, requiring retraining or adjustment when encountering new unknown objects to cope with changes in data distribution.
Open World Recognition and Detection differs significantly from Open Set Object Recognition in that it uses dynamic datasets, capable of continuously incorporating new known categories in a manner akin to continuous learning. Bendale and Boult [23] first introduced the concept of the Open World, revolutionizing the traditional static classification approach based on training with a fixed set of categories. The proposed setting requires models to recognize both known and unknown categories simultaneously. Additionally, Pernici et al. [24] investigated the problem of face identity learning in the open world, while Wu et al. [25] proposed a method using visible category sets to match new samples.
In summary, the open world recognition and detection work can better adapt to the changing environment by using dynamic data sets and flexible settings, and make corresponding updates when encountering new categories.
Joseph et al. [2] first introduced the concept of Open World Object Detection (OWOD), breaking the limitation of traditional frameworks that only recognize known categories, enabling models to process new categories. In OWOD, models need to recognize both known and unknown objects, and label unknown objects to update the model and adapt to changing environments. This poses numerous challenges: generating accurate bounding boxes for known categories and high-quality candidate regions for unknown objects, distinguishing between known objects, backgrounds, and unknown objects, and detecting objects of different sizes while effectively constructing contextual associations between them.
To address the challenges in OWOD, Joseph et al. [2] proposed the ORE algorithm based on Faster R-CNN. ORE utilizes the Region Proposal Network (RPN) to generate category-independent candidate regions, labels candidate regions that do not overlap with known object ground truth boxes and exhibit high “objectness” scores as unknown, and separates categories using latent space clustering techniques. At the same time, an energy-based binary classifier is used to further distinguish between unknown and known classes. Despite progress, ORE still struggles to adapt to the open world. OSODD [3] enhances performance through domain-agnostic augmentation, contrastive learning, and semi-supervised clustering. Zhao et al. [4] improves the quality of pseudo-labels for unknown objects by using non-parametric Selective Search [26] instead of the unknown-aware RPN. OpenDet [27] distinguishes between known and unknown objects by separating high-density and low-density regions in latent space.
The task of open world object localization is inherently similar to the localization component of object detection. Object detection encompasses both localization and recognition tasks, with many previous studies implementing object detection through these two stages. Firstly, the localization stage identifies bounding boxes for potential objects in the image. Subsequently, these bounding boxes are passed to the classification stage for categorizing each object. Taking Faster R-CNN [28] as an example, its classification stage relies on bounding boxes generated by the RPN, a method that has proven effective across multiple datasets. However, due to the close dependence of the classification stage on the results of the localization stage, the object proposals generated in the localization stage often overly conform to known categories in the training data, leading to poor performance when facing unknown categories, and prone to false positives or missed detections.
In early object detection methods, techniques such as selective search [26] and edge detection [29] were used to generate category-agnostic proposals, which provided training samples for the subsequent classification tasks in object detection. These methods also provided inspiration for open world object localization. With the development of deep learning, RPN [28] and its improved versions [30-31] learned to identify regions with a high probability of containing objects. However, RPN tends to overfit to known categories. To address this issue, the Object Localization Network (OLN) [5] replaced the category-agnostic classification head of Faster R-CNN with a localization quality prediction head, thereby avoiding treating unknown objects as background. Zhao et al. [4] proposed an auxiliary module that uses a non-selective search method to generate category agnostic proposals, assisting the RPN in generating object proposals. The aim was to reduce the probability of RPN overfitting to known categories. Saito et al. [32] employed background-erasing augmentation and multi-domain training strategies to reduce the bias of classification-based proposal networks. Gao [33] leveraged the idea of semi-supervised learning, using pseudo-labels to enable the model to learn unknown object categories.
III. METHODS
This paper employs FCOS [6] as the backbone network and addresses three challenges encountered during model training. Firstly, when localizing objects of unknown categories, it faces the scarcity of low-quality object samples. Secondly, in the process of object classification, background samples are susceptible to contamination from unlabeled samples that possess prominent object features. Thirdly, the model struggles to effectively differentiate between known and unknown samples, leading to misclassification of unknown samples during the classification phase. To tackle these challenges, this section will delve into the potential causes and propose corresponding solutions.
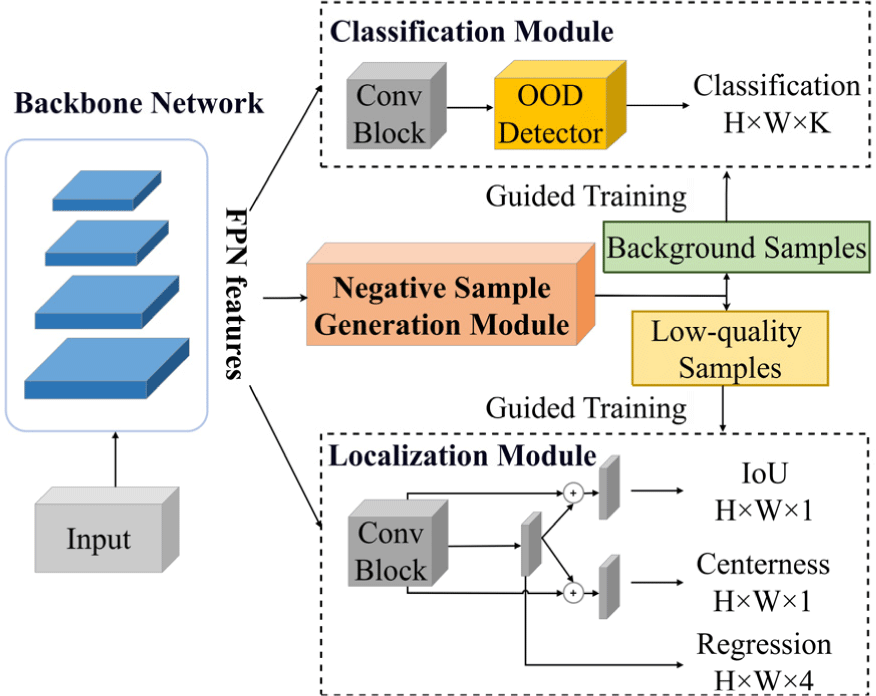
The overall framework of the network, as illustrated in Fig. 2, primarily comprises two crucial components: a negative sample generation module and an unknown class sample filtering module based on the OOD detector [34]. The method presented in this chapter is an improvement upon FCOS [6]. In the localization module, the model incorporates existing enhancements tailored for FCOS. Specifically, FCOS utilizes the centerness metric to estimate the objectness of candidate regions. However, research has shown that Intersection over Union (IoU) is also an effective method for measuring objectness. To better extract object features and improve the accuracy of bounding box predictions, some work integrates an IoU branch into the localization module, which works in conjunction with the centerness branch to jointly assess the quality of candidate bounding boxes. This enables the model to generate more precise and higher-quality object candidate boxes. The formulas for calculating IoU and centerness are provided below:
where [l*, r*, t*, b*] denotes the ground truth bounding box corresponding to the object region, while [l, r, t, b] represents the distances from the center point of this region to the left, right, top, and bottom sides of its ground truth bounding box, respectively.
To further enhance performance, some advanced models combine features extracted from the backbone network with those from the regression branch, which are then processed through convolutional layers to produce corresponding outputs. In this chapter, this structure is referred to as the Conditional Head. This paper adopts this structure and additionally introduces an OOD detector [34] in the classification module, aiming to filter out unknown class samples.
During the overall training process, the negative sample generation module is first trained to provide low-quality samples or background samples for subsequent model training. In the formal training phase, the features generated by the feature extraction network are fed into the negative sample generation module, as well as the classification and regression branches of the model’s detection head. The classification branch utilizes the background samples generated by the negative sample generation module, combined with its original positive samples, for training. This reduces the likelihood of high-object unannotated samples appearing in the background samples. The localization branch is trained using samples from center point sampling and the lower-quality object samples generated by the negative sample generation module. This improves the balance between high and low localization quality samples, preventing the model from focusing solely on highly object-like samples and reducing the risk of misclassifying unknown category samples as low-quality samples. Simultaneously, the model utilizes the OOD detector [34] to filter out unknown class samples, which are then passed to the classification branch, enhancing the model’s classification accuracy for known class samples.
In open world learning tasks, existing research has primarily focused on screening high-quality positive samples, with less attention given to negative samples. This has led to models becoming overly reliant on feature-prominent object samples while neglecting the learning of low-quality and background samples, thereby limiting model performance. To address this, this section proposes a negative sample generation module designed to produce background samples or low-quality samples with weaker features. This module not only enhances the diversity of training samples and maintains sample balance but also reduces the risk of the model learning erroneous features, thus improving the quality of object candidate regions.
OLN [5] as an open world object localization network, possesses the ability to generate high quality object candidate boxes that are not limited to known categories. It abandons traditional dependence on category information and instead utilizes geometric cues to accurately estimate the localization quality of candidate regions, thereby effectively identifying objects. The localization quality score accurately reflects the likelihood that a candidate region belongs to an object, enabling OLN to easily distinguish between samples with prominent object features, samples with less prominent features, and purely background regions, as shown in Fig. 3.

Therefore, we utilize the OLN model [34] as the negative sample generation model and append a sample classifier at its tail. This classifier divides candidate samples into three categories based on their scores: high-quality samples with prominent object features, low-quality samples with less prominent object features, and background samples. Low-quality and background samples are collectively defined as negative samples and are applied to the localization and classification branches of the model, respectively. This design allows both branches to effectively learn relevant sample features, significantly improving model accuracy. The network framework is illustrated in Fig. 4.
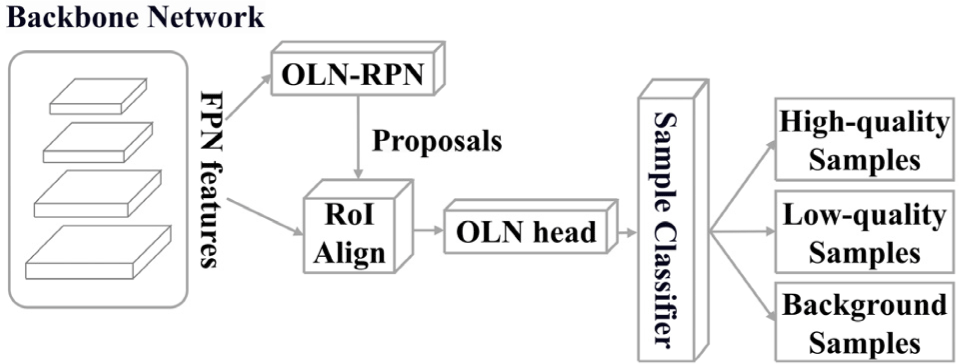
With this setup, the OLN model classifies candidate boxes to extract samples with less prominent features and background samples. The model’s predictions range from [0,1] and are categorized into three intervals based on thelocalization quality score: above 0.7, between 0.3 and 0.7, and below 0.3. Specifically, samples with a localization quality score above 0.7 are highly likely to contain objects and typically exhibit distinct object features. Samples scoring between 0.3 and 0.7 are identified as low-quality samples with relatively less prominent object features. Meanwhile, samples with scores below 0.3 are considered background regions, lacking clear object features. The classification method is detailed below:
where S denotes the samples generated by the negative sample generation module, “score” is the localization quality score of sample S, Sh represents high-quality samples, Sl represents low-quality samples, and Sbg represents background samples.
Despite previous open world object localization methods enhancing the model’s ability to mine sample features by combining the centerness branch and the IoU branch, there are still deficiencies in the sample sampling process. Firstly, since both centerness sampling and IoU sampling select samples based on the positional and shape relationships between the samples and the ground truth boxes, the high-quality samples selected by the two methods may overlap in terms of features. This means that during training, the model may repeatedly learn certain specific features.
Secondly, the IoU sampling method relies on the ground truth boxes of known categories to screen low-quality samples, which has its limitations. It may mistakenly classify candidate regions with obvious object features as low-quality samples. This is because IoU calculation is primarily based on the overlap between the candidate box and the ground truth box, rather than the objectiveness of the candidate box itself. Therefore, when the IoU value between a candidate box and a ground truth box is low, even if the candidate box actually contains a clear object, it may be misclassified as a low-quality sample. This misclassification can lead the model to learn incorrect features, thereby affecting the accuracy of its object localization.
To address the above issues, this chapter abandons IoU sampling based on existing work. Instead, it only adopts the centerness sampling method to collect high-quality object samples for the model and utilizes samples with localization quality scores between 0.3 and 0.7 from the negative sample generation module as low-quality object samples. With this approach, the localization module can not only learn the features of high-quality samples with prominent object features but also learn the features of low-quality samples more accurately. This capability enables the localization module to better distinguish samples with different features. Such a strategy enhances the model’s ability to recognize and locate samples of different qualities.
Ensuring the model’s localization accuracy in an open world while improving its ability to accurately recognize known categories is a key challenge in open world learning. To address this issue, a method called Unknown Object Masking has been proposed. This method, for the first time, optimizes background samples by reducing the interference of unlabeled object samples on the model, thereby enhancing the model’s ability to distinguish unlabeled object samples from background samples.
The core of this method lies in hiding background regions that contain potential object features to prevent these regions from being mistakenly sampled as background samples. However, this masking strategy cannot fully cover all unlabeled objects in the image, making it impossible to form a completely continuous masked area. This can lead to unlabeled objects still being mistakenly collected as background samples during background sample collection. Additionally, discontinuous masked areas can hinder the model’s learning of background information.
We use the negative sample generation module to solve this problem. This module selects samples with localization quality scores less than 0.3 as background samples, replacing the background samples originally collected through the Unknown Object Masking method. In this way, the model can obtain more accurate and pure background samples, thereby better learning background features and improving overall object detection performance.
Open world learning tasks introduce a large number of candidate bounding boxes belonging to unknown categories. Due to the lack of effective training to distinguish between known and unknown category objects, this may increase the risk of unknown category objects being mistakenly identified as known categories. To reduce the risk posed by unknown category samples during the classification stage and ensure the detection accuracy of the model for known categories, we adopt an offline OOD detector to identify and eliminate unknown classes from the samples. The main advantage of this approach lies in its flexibility and compatibility, as the offline OOD detector can be integrated into different object detection models as an independent module without requiring any specific modifications to the model itself. Additionally, this offline framework design also addresses potential objective conflicts between object detection and OOD detection tasks.
Specifically, this method employs the offline OOD detector proposed by Liu et al. [34], which trains and fine-tunes the DINO model using data from known categories. In this process, the OOD detector is configured as a classifier with K+1 output categories, where K represents the number of known object categories. The additional category is dedicated to identifying samples that do not belong to the known categories, including both unknown category samples and potential new category samples. Unlike previous research that requires a large amount of additional OOD data for training, this method only uses labeled data from known categories for training. It categorizes all samples that do not belong to known categories (including unknown category samples and background samples) as OOD category samples. During training, the IoU between the ground truth boxes and candidate regions is compared, and regions with lower IoU values are classified as OOD category samples, as these regions are likely to contain unknown category or background samples.
Although treating background samples as OOD is not the most ideal choice, this method provides an effective mechanism for the model to distinguish between known and unknown category samples during the learning process, thereby reducing the risk of unknown categories appearing in subsequent classification stages. To distinguish whether a object sample belongs to a known category or the OOD category, this method introduces the Mahalanobis Distance to calculate the threshold γood for the OOD score, with the specific formula as follows:
where f(x) represents the intermediate feature vectors extracted from the candidate regions in the image by the DINO model, and denotes the estimated mean vector of the category, which reflects the average manifestation of that category in the feature space. as the estimated variance matrix, describes the correlation and variation among the dimensions of the feature vectors. Before classifying the candidate bounding boxes, this method calculates the OOD score for all samples and compares it with a preset threshold γood. If a sample’s score exceeds γood, it is classified as a known category and sorted into the corresponding classification. If a sample’s OOD score falls below γood, it is identified as an OOD sample and removed from the dataset.
This method effectively reduces the number of unknown category samples at the classification stage, thereby decreasing the likelihood of misidentifying unknown categories as known ones. Such processing enhances the model’s performance in detecting known categories.
IV. EXPERIMENTS
To verify the effectiveness of the proposed method, we conducted the following experiments. First, we performed ablation studies to analyze the contribution of each module. Second, for the open world object localization task, we compared the impact of IoU scores, centerness scores, and different sampling methods on improving candidate box quality. Additionally, we conducted a visual analysis of different negative sample generation modules to validate the reliability of OLN. Finally, we compared our model with mainstream methods on the COCO dataset to evaluate its detection performance in open world learning tasks.
Experimental Data: In this study, we primarily used the MS COCO dataset [35] for experiments and evaluation. To ensure fairness in the evaluation, the COCO dataset was divided into 20 known categories, which are present in PASCAL VOC [36], and 60 unknown categories, which do not appear in PASCAL VOC. During the training phase, the model was trained exclusively on the 20 known categories, while during the evaluation phase, it was tested on the 60 unknown categories. To ensure that the evaluation focuses on the model’s ability to detect unseen categories, annotations of known categories were ignored during the evaluation process.
Evaluation Metrics: In the open world object localization task, the model’s performance is evaluated using the Average Recall (AR) metric. This metric assesses the model’s performance by calculating the recall of unknown categories within the top N generated candidate boxes. Here, N refers to the number of candidate boxes considered during the evaluation. For the open world object classification task, performance is evaluated using the Average Precision (AP) metric. This metric is calculated by first computing the average precision for each category in the known category set, and then averaging these average values.
Experimental Details: The algorithm in this paper uses FCOS as the baseline network. The experiments were conducted on an Ubuntu 18.04.5 operating system, with an Intel Xeon Silver processor, Python version 3.7, and the deep learning framework PyTorch 1.7.1. The GPU used is Nvidia GeForce RTX 3090, with two cards providing a total of 48 GB of VRAM. The initial learning rate for all experiments was set to 0.001.
To validate the effectiveness of the method proposed in this paper, we conducted experiments on the low-quality sample substitution method, the background sample substitution method, and the unknown-category sample filtering method based on an OOD detector, within the frameworks of open world localization tasks and open world classification tasks, respectively.
Table 1 shows the experimental results of replacing the traditional IoU sampling method with the low-quality sample replacement method in the open world localization task.
| Method | COCObase | COCOnovel | ||
|---|---|---|---|---|
| AR10 | AR100 | AR10 | AR100 | |
| FCOS | 55.33 | 59.23 | - | - |
| OWP | 34.52 | 54.10 | 14.51 | 31.26 |
| OWP+NS | 35.67 | 55.45 | 15.78 | 32.33 |
Here, OWP refers to the model that combines the centerness branch with the IoU branch, using the Conditional Head and joint sampling of centerness and IoU. NS refers to the low-quality sample replacement method. According to the data in Table 1, it can be seen that the low-quality sample replacement method improves the model’s localization accuracy for unknown categories, resulting in a 1.27% and 1.07% increase in AR10 and AR100, respectively. This validates the effectiveness of the low-quality sample replacement method in open world object localization tasks.
Table 2 presents the experimental results of using the background sample replacement method and the OOD-based unknown class sample filtering method in the open world classification task. These methods are designed to improve the model’s recognition performance for known category objects. In Table 2, the background sample replacement method replaces the unknown object masking method. The background sample replacement method provides the model with cleaner background samples, which helps the model better distinguish between foreground and background. Additionally, by introducing the OOD-based unknown class sample filtering method, samples from unknown categories can be removed from the classification branch, allowing the model to focus more on classifying known categories.
In Table 2, “joint” refers to training with both open world localization and classification branches jointly; “unknown” refers to the addition of the unknown object masking method; “BS” stands for the background sample replacement method; and “OOD” indicates the introduction of the OOD-based unknown class sample filtering method.
Overall, the experimental results in Table 2 demonstrate the effectiveness of the background sample replacement method and the OOD-based unknown class sample filtering method in the open world classification task. Both methods help improve the model’s performance when handling known categories.
This section compares several methods for improving the quality of object candidate box predictions. Specifically, this experiment incorporates three localization quality metrics: centerness, IoU, and the square root of the product of centerness and IoU (). Two sampling strategies were adopted: center sampling, which selects samples based on the centerness of the candidate boxes, and IoU sampling, which selects samples based on the IoU of the candidate boxes. Additionally, a low-quality sample substitution method (NS) was introduced to provide low-quality samples with less prominent features.
The experimental results are shown in Table 3. In this table, “conditional” refers to the method that combines features extracted by the backbone network and features from the regression branch in the convolutional layer to predict the localization quality score. This approach more effectively utilizes information in the network, thereby improving the quality of candidate boxes. “CS” refers to the centerness sampling method, and “IS” refers to the IoU sampling method.
By analyzing Table 3, it can be observed that using Conditional IoU-CS-NS produces the highest quality object candidate boxes.
In open world object localization tasks, learning negative samples is crucial for the model’s performance. As shown in Fig. 5, there are significant differences in localization performance across different negative sample generation modules. Traditional methods often fail to accurately distinguish between high-quality object samples, low-quality object samples, and actual background, and this lack of distinction can lead to the model learning misleading information, which in turn affects the experimental accuracy. The method in this paper references the open world object localization model (OLN), which can more reliably provide low-quality or background samples.

Fig. 5 shows the negative samples generated by different models for the same image. It is clearly observed that the OLN method demonstrates higher precision in generating negative samples. In contrast, the RPN model fails to avoid unmarked objects in the generated negative samples, indicating its relatively weak ability to filter negative samples. This experiment demonstrates that the OLN method can provide more accurate negative samples for model training, reducing the interference of erroneous information, and thus helping to improve the accuracy and robustness of the model in open world object localization tasks.
However, during the experimental process, we observed that the model’s performance would be affected to a certain degree when it was exposed to low-light scenarios. This is primarily because low-light conditions limit the clarity and contrast of images, posing greater challenges for the model to distinguish between targets and backgrounds. Specifically, in such environments, some of the negative samples generated by the model may contain larger object regions, as illustrated in Fig. 6. Consequently, further refinement of the model is required in the future to enhance its accuracy in complex scenarios.

In this section, to validate the effectiveness of the proposed method, a comparison is made with other existing methods. These comparisons are divided into two main parts: the first part focuses on the open world object localization task, and the second part focuses on the open world object classification task. The specific results are shown in Table 4.
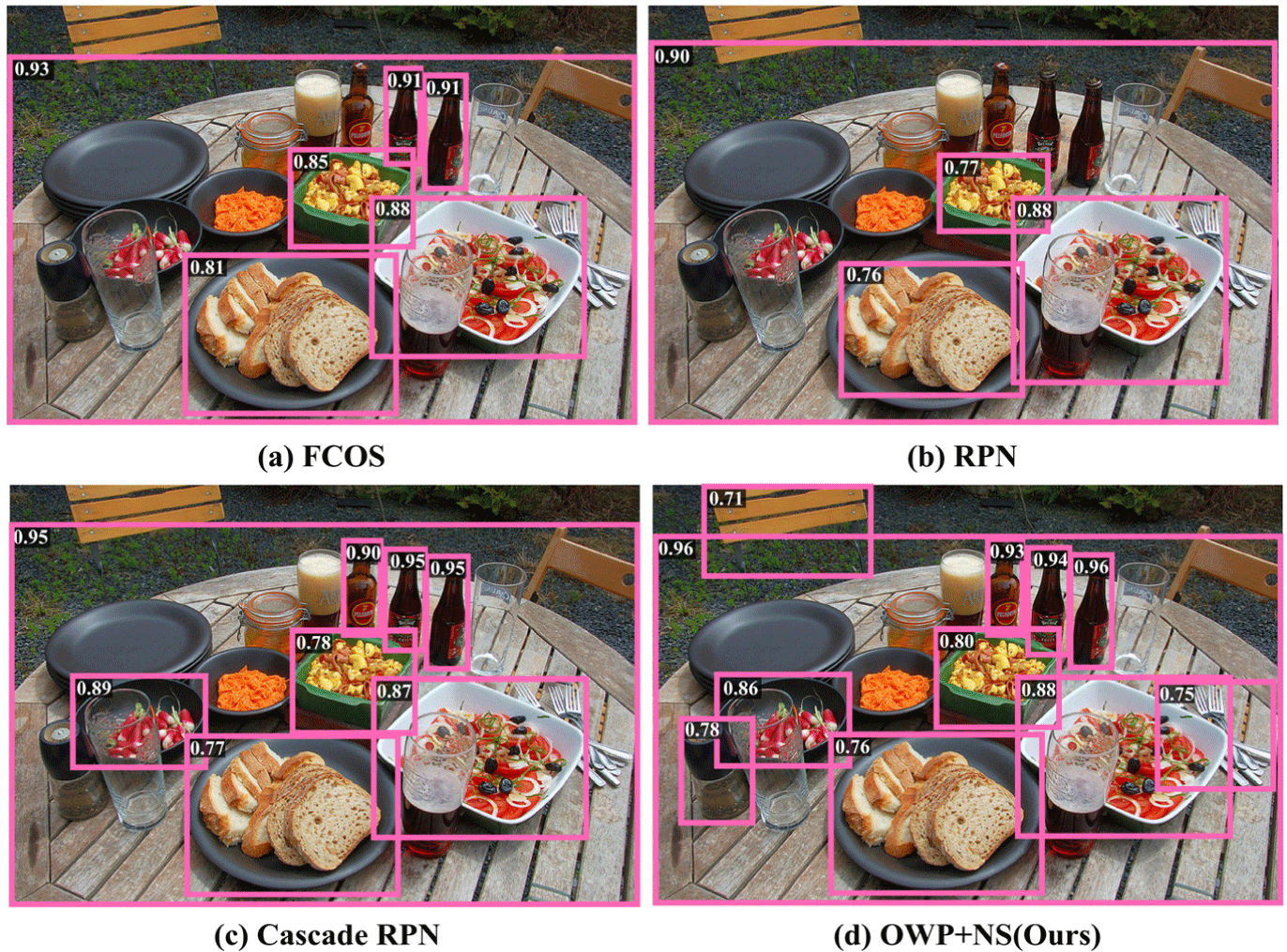
In the localization task, using the binary classification FCOS as the baseline network, it can be observed that the proposed method significantly outperforms one-stage open world object localization methods, such as RPN and IoU-aware. Additionally, the proposed method also outperforms some two-stage open world object localization methods, such as Cascade RPN. For intuitive comparison, we have visualized the localization results obtained by methods including FCOS, RPN, Cascade RPN, and OWP+ NS. As illustrated in Fig. 7, our method demonstrates significantly better localization performance, detecting more objects than the others.
In the classification task, FCOS is also used as the baseline network. In Table 4, “joint” refers to training with both the OWP and classification branches combined, “unknown” refers to the addition of the unknown object masking method, “Class-Aware OLN” refers to the addition of OLN to the classification branch, “BS” refer to the background sample replacement method, and “OOD” refers to the introduction of the Out-of-Distribution detector-based unknown class sample filtering method. Through comparison, it is found that the proposed method achieves the best perform-ance in both the detection accuracy for known categories and the localization accuracy for unknown categories. We have visualized the detection results for known classes using methods such as FCOS, joint (OWP+Classification), joint+unknown, and Joint+BS+OOD. As illustrated in Fig. 8, our detection results are more accurate. Specifically, our method detects more instances of sheep and correctly identifies dogs. In summary, the proposed method demonstrates excellent performance in both open world object localization and classification tasks, effectively improving the model’s detection capability for known categories and localization accuracy for unknown categories.

V. CONCLUSION
Addressing issues such as sample imbalance, unstable sampling strategies, and decreased recognition accuracy for known categories in open world object localization tasks, this paper proposes an improved method based on negative sample learning. By designing a negative sample generation model, we produce high-quality negative samples and low-quality object samples, effectively mitigating the sample imbalance problem and reducing the risk of the model learning incorrect features. Additionally, an offline OOD detector is used to filter unknown samples before classification, minimizing interference with known categories’ accuracy. Experimental results demonstrate that the proposed method significantly enhances the localization and classification accuracy of the model on the COCO dataset, validating its effectiveness. The work presented in this paper offers a novel solution for open world object localization tasks, enabling better handling of unknown category objects while maintaining high recognition accuracy for known categories. Future research can further explore how to integrate incremental learning to enable the model to progressively expand its recognition capabilities for unknown categories.



