
I. INTRODUCTION
Marvel Studio is one of the dominant players of film industry. The evolution of Marvel Cinematic Universe (MCU) has arisen from superhero comics from 1960-1970s. The idea of bringing superheroes into single fictional universe was Marvel’s empire-building model [1]. However, the release of “Guardians of the Galaxy (2014) indicated the slight change in the business model of Marvel studio [2]. Subsequently, studio has expanded its focus on creating new characters. Updated business model has brought the MCU to create phenomenal series of “Avengers”. As a result, “Avengers: End Game (2019)” made a colossal impact on the global box office [3]. However, the primary plot of the MCU afterwards became more disorganized, incoherent, and complex. Haoran Qiu argues that The Phase Four of the Marvel Cinematic Universe features far from too much of same formulaic cinematography, which gradually reduce the interest of audience [4].
The concept of Shapley Additive exPlanations (SHAP) values, introduced by Scott Lundberg and Su-In Lee in 2017, epitomizes this pivot. SHAP values offers a coherent and individualized approach to elucidate the contribution of each feature in a models’ prediction, akin to examining the motives and actions of each character in the MCU narrative. This study leverages the analogy of the MCU, utilizing SHAP values to classify Marvel characters into the archetypes of ‘good’ and ‘evil’ based on a range of attributes and skills. This unique application not only serves as an accessible introduction to the versatility of SHAP values but also allows for a deeper exploration of complex traits and moral alignments within a familiar context.
Our contribution through this novel intersection of AI interpretability and pop culture is twofold: 1) We provide a methodological bridge between complex AI systems and the general public, and 2) we demonstrate the utility of SHAP values in unpacking the layered elements of character-driven narratives. Furthermore, by analyzing the classification of Marvel characters with SHAP values, we offer readers a compelling glimpse into the power of explainable AI, reinforcing its significance in an increasingly automated world.
The paper progress from a review of the relevant background, through the methodology and analysis of SHAP values, to a discussion of the results, concluding with the study’s limitation and potential direction for future research.
II. BACKGROUND AND RELATED WORK
SHAP values, inspired by Lloyd Shapley’s cooperative game theory, have transformed the way we interpret machine learning models [5]. KernelSHAP and TreeSHAP stand out in the SHAP framework for their efficiency in computing SHAP values but are part of a larger array of strategies that apply game theory principles to machine learning [6]. These techniques are particularly notable for their computational efficiency, enabling the practical application of SHAP values in various machine learning models, from simpler linear regressions to complex ensemble methods.
SHAP values have been used extensively in fields where critical decisions are made. In medical field, SHAP values help elucidate why AI models identify certain conditions, like cancer, by pinpointing influential features in predictions [7]. While SHAP values have been primarily utilized in critical areas, their application in character classification, particularly in a narrative or fictional context like the Marvel Universe, remains less explored. Current work is conducted to fill the gap by analyzing Marvel characters’ classifications based on their skill sets, utilizing SHAP values to interpret these classifications.
III. METHODOLOGY
To facilitate an inclusive understanding of our experimental process, we have delineated the methodology through a structured flow chart illustrated in Fig. 1. As for data collection, we opted for a publicly available dataset, which includes Marvel characters and their skills, along with their alignment as ‘good’ or ‘bad’ in the movies [8]. Boolean features were converted to binary (0 and 1) for analysis. Addressing missing values was a significant step in data preprocessing. We postulated that the absence of information likely indicates a lack of skill, hence missing values were replaced with 0.
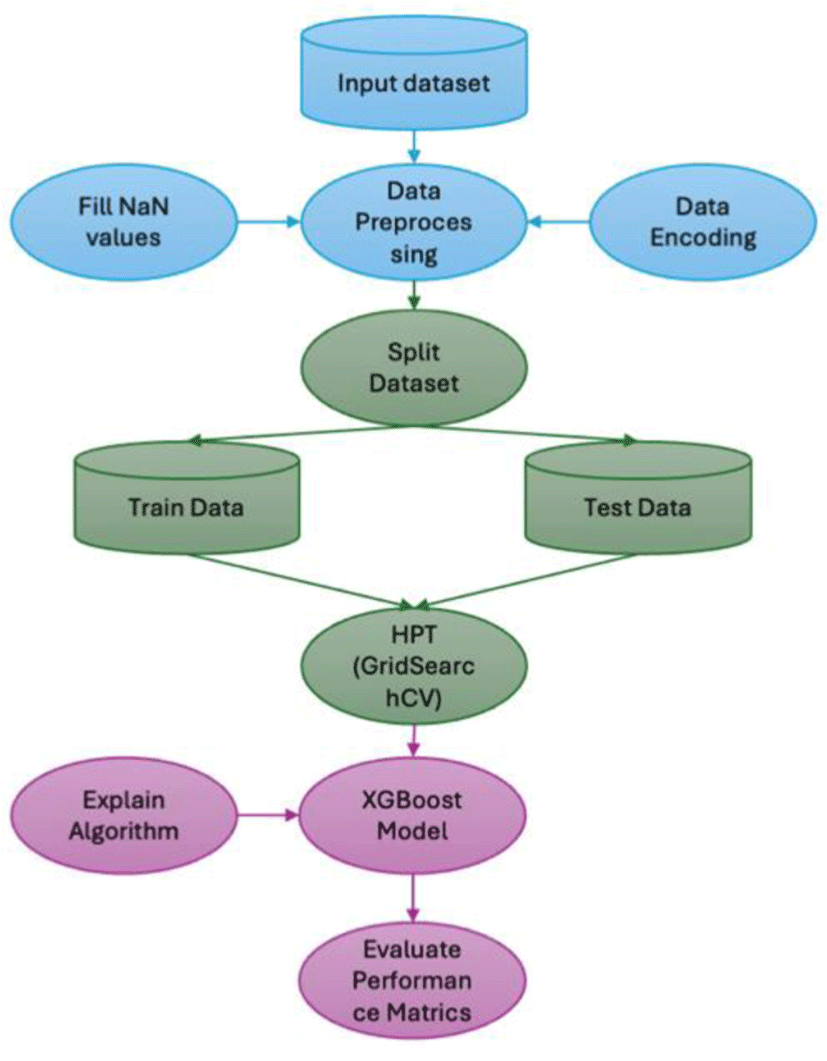
The final composition of the dataset revealed a predominance of ‘good’ characters, constituting 68% of the data, with ‘bad’ characters making up the remaining 32%. We have employed SMOTE technique to overcome the unbalancing in the dataset [9].
For the classification task, the XGBoost Classifier was our algorithm of choice, elected for its well-documented robustness, computational efficiency, and the convenient tuning of its hyperparameters. XGBoost has demonstrated exemplary performance across a spectrum of classification challenges, adeptly managing various data types and intrinsic handling of missing values [10]. Hyperparameter optimization was conducted via GridSearchCV, which systematically worked through a range of combinations to pinpoint the optimal parameters, enhancing the model’s ability to generalize. We decided to allocate 80% of dataset for training purposes and reserving 20% to evaluate the model’s performance, respectively. The GridSearchCV process concluded with the identification of the most effective hyperparameters for our XGBoost model: a learning rate of 0.1, a max_depth of 5, n_estimators set to 300, and a colsample_bytree of 0.3. There parameters yielded the highest test score of 0.78.
The model effectively predicted true positives and true negatives, but it struggled with misclassification of false negatives. This outcome highlights the need to understand model limitations when interpreting SHAP values. The accuracy and reliability of SHAP values are contingent upon the overall performance and tuning of the underlying model.
IV. SHAP VALUES ANALYSIS
The computation of SHAP values was conducted using the open-source Python library SHAP, which is designed for explainability in machine learning [11]. The Tree Explainer module, a component of the SHAP library specifically optimized for tree-based models like XGBoost, was utilized to calculate the SHAP values for each prediction.
In Fig. 2, the SHAP summary plot for a true positive prediction reveals a contrasting scenario. The feature ‘Jump’, when present, is the most influential in swaying the model towards a true positive prediction, indicative of a ‘heroic’ alignment. ‘Invulnerability’ and ‘Accelerated Healing’ also contribute positively to the model’s confidence in making a true positive classification. Interestingly, the absence of features like ‘Super Strength’ negatively influences this outcome.
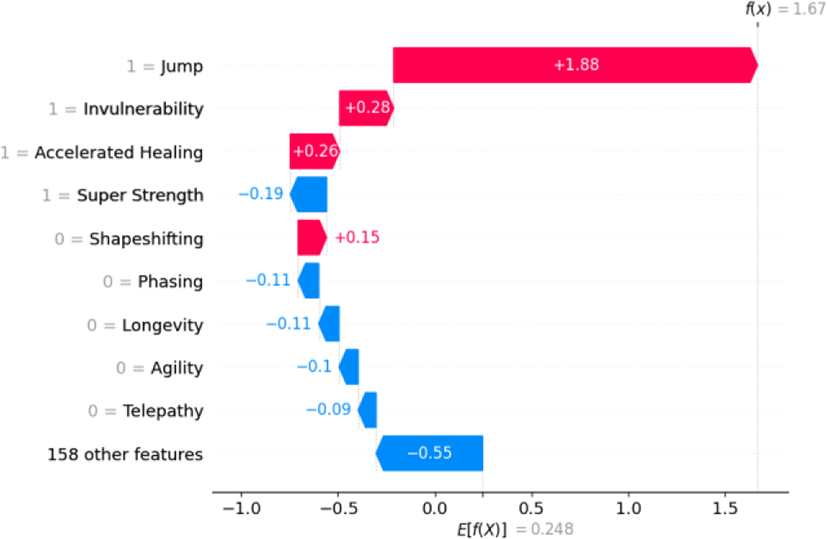
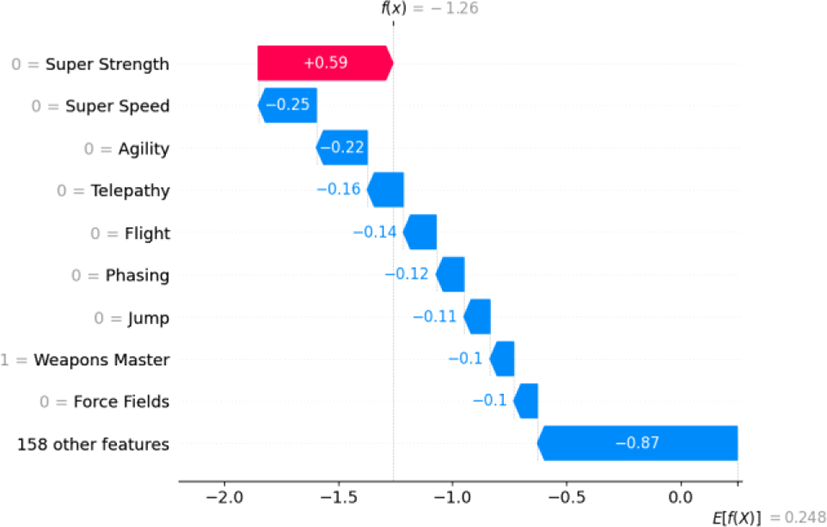
Fig. 3 offers a SHAP value summary plot detailing the model’s rationale when predicting a true negative outcome, which, in the context of the study, may refer to the classification of a character as a ‘villain’ or possessing a negative trait. The plot explains that the absence of ‘Super Strength’ is the most significant positive driver for such a prediction, as evidenced by its high positive SHAP value. The features ‘Super Speed’, ‘Agility’, ‘Telepathy’, among others, when absent, also tend to influence the model toward a true negative classification, albeit to a lesser extent. Conversely, the presence of ‘Weapons Master’ has a slight negative impact on the prediction. Collectively, these feature effects illuminate the intricate interplay between various superhero attributes in shaping the classification decision.
These examples underscore the value of SHAP in model interpretation, revealing not just the features that influence predictions, but also highlighting the need for careful consideration of the model’s baseline tendency. SHAP’s detailed, instance-level explanations provide insights that are critical for understanding, validating, and improving the model’s decision-making process.
V. RESULTS AND DISCUSSION
The application of the XGBoost classifier, supplemented by SHAP value analysis, yielded notable insights into the classification of Marvel characters as ‘good’ or ‘bad’. The model achieved an accuracy of 74%, with precision, recall, and F1 scores reflecting a reasonable predictive performance given the complexity of the task.
The true positive predictions highlighted an interesting trend: characters with abilities like ‘jump’ and ‘invulnerability’ were most classified as ‘good’. These findings align with common superhero tropes where such abilities are emblematic of heroism. Conversely, the analysis of false negatives revealed that the model occasionally misclassified ‘bad’ characters as ‘good’. Notably, skills typically associated with villainy, such as ‘Super Strength’ and ‘Energy Blasts’, surprisingly contributed negatively to these misclassifications, suggesting that the model might have learned an unintended bias from the training data.
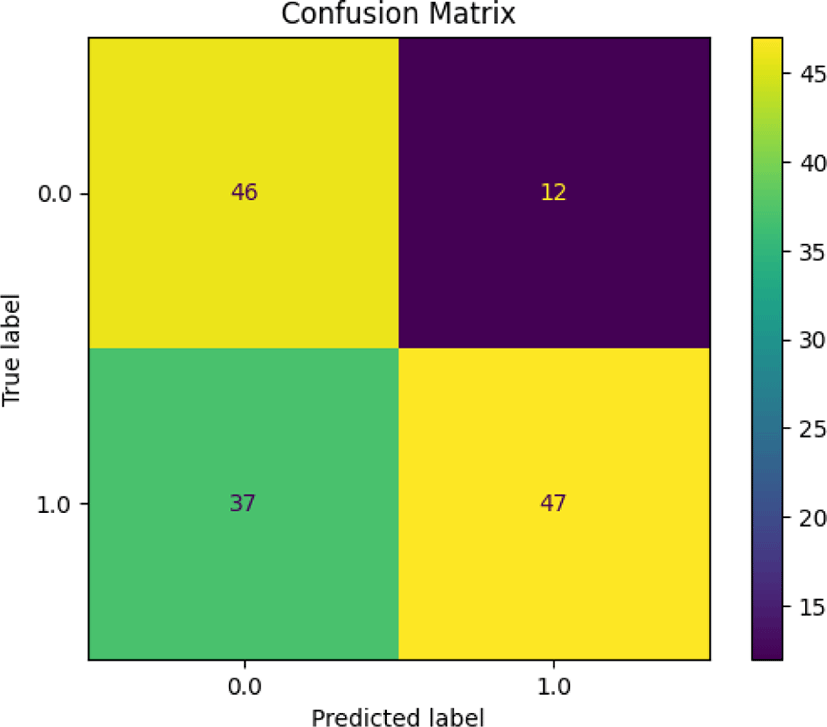
Based on the confusion matrix presented in Fig. 4, true negative predictions were less frequent, indicating a skew towards ‘good’ character classifications. This skewness in the model’s predictions underscores the need for a more balanced dataset that encompasses a wider array of ‘bad’ character traits. The false positives were minimal, indicating that the model was generally successful at identifying ‘bad’ characters when the data presented a clear set of villainous traits.
The SHAP value analysis provided a granular view of the model’s decision-making process, revealing that certain abilities have a stronger influence on character alignment predictions than others. This level of interpretability is crucial for understanding how the model processes information and which features it deems most important. The insights from SHAP analysis extend beyond model performance, suggesting a deeper narrative structure within the data. The analysis suggests that certain character abilities are culturally and narratively associated with moral alignments in the Marvel Universe. These insights could be highly influential for the advancement of AI in narrative analysis and entertainment, guiding content creators in understanding audience perceptions of character traits.
We have selected Python 3.10 as the development language for machine learning. Anaconda environment was chosen for its flexible package administration [12]. The experiment was conducted on a 14-inch MacBook Pro with Apple M1 Pro chip and 16 GB RAM memory. The operating system is running on macOS. To facilitate programming, Visual Studio Code is used as the development environment. The code supporting the findings of this study is available upon request.
VI. LIMITATION AND FURTHER RESEARCH
The study’s limitations include the limit size of dataset and the absence of new Marvel characters like Ms. Marvel. Another limitation is the potential overrepresentation of ‘good’ character traits in the dataset. Additionally, potential biases in the AI model’s decision-making process could be assessed and mitigated in subsequent research. Exploring the effects of algorithmic biases on character classification could ensure a fairer representation of diverse character traits. While we employed SHAP tool, further research could use other interpretability tools, such as Local Interpretable Model-Agnostic Explanations (LIMA) and Shapley Interaction Quantification (SHAP-IQ) [13-14].
VII. CONCLUSION
To sum up, this research addresses the classification of marvel cinematic universe characters and interpretability of such classification. We employed XGBoost decision tree model on the preprocessed dataset of Marvel characters. This research contributes to the growing body of work in explainable AI, demonstrating the utility of SHAP values in interpreting complex classification models. The findings provide a foundation for further exploration into the character development, potentially guiding the creation of unique and resonant superhero personas. This work not only highlights the relevance of AI in media and the entertainment but also its role in enhancing our comprehension of complex storytelling elements.

