
I. INTRODUCTION
Three-dimensional (3D) object detection is considered important in computer vision applications that are deeply related to the real world, such as augmented reality, autonomous driving, and robotics. Most 3D object detection methods use RGB image as input with sensor devices that provide depth information such as LiDAR and Radar. Although LiDAR-based research [1-4] has developed a lot, interest in camera-based [5-11] has recently increased. This is because LiDAR is too expensive, and information on far away objects is not available. Also, the LiDAR point cloud is also very sparse, so very efficient transformation algorithm is required. Camera-based 3D object detection is much more advantageous in aspect of price and has rich information about far away objects. However, the disadvantage is that the accuracy is lower than the methods using sensor devices because the depth information must be estimated only based on the images.
Survey work for various approaches of 3D object detection has been published several times before [12-13]. However, existing survey works [12-13] have mainly explained the difference between the modality methods, such as camera based, point cloud, and sensor fusion. In this paper, we will make survey of the latest models for 3D perception and classification with only camera image. In particular, an analysis of the multi-view-based method that has recently getting attention is also included. There are three approaches for image-based object detection, which is depending on the number of cameras used.
The first is monocular-based 3D object detection [5-6], which is an approach of detection using only one image from a camera as an input. To predict 3D information of the objects of interest, the depth information must be obtained well. Since only one camera is used, there is a problem that it is difficult to estimate information on depth. To solve this problem, some methods have recently been introduced to predict 3D information by utilizing geometry prior. Nevertheless, monocular-based methods perform poorly compared to other methods due to lack of informative features.
The second approach is stereo-based 3D object detection [7-8], which utilizes disparity estimation for two images obtained by placing two cameras on the left and right sides. Since more accurate information on depth can be obtained by disparity estimation, comparable performance can be achieved even when compared to the LiDAR-based methods.
The last approach to introduce is multi-view 3D object detection [9-11]. The multi-view method utilizes multiple cameras in the ego car to make the field of view surrounding the car as input. In the existing monocular and stereo methods, 3D object detection and map segmentation were considered as separate tasks. However, a technique using multi-camera images has the advantage of being able to generate a BEV feature map centered on ego cars.
This work focuses on reviewing the state-of-the-art approaches for monocular, stereo, and multi-view 3D object detection mentioned above. We summarize the challenges and discuss the future research.
II. IMAGE-BASED 3D OBJECT DETECTION
Monocular 3D object detection is a task that estimates 3D information such as location, direction, and size of an object of interest using a single image as an input. Only by augmenting the 2D image feature or designing an efficient algorithm, the available feature can be refined. To solve the problem of severely lacking depth information compared to LiDAR-based methods [1-4, 12-13] or other camera-based methods [5-11], geometry prior is recently being used together.
Geometry Uncertainty Projection Network for Monocular 3D Object Detection (GUPNet) [5] proposed a GUP module that represent the inferences for depth as distributions using the geometry information. Since it uses depth as a continuous value rather than a discrete value, more accurate depth estimation is possible. As you can see in Fig 1, the GUP module estimates the depth as the distribution form. Another key design of GUPNet is hierarchical task learning (HTL) algorithm. 2D/3D height estimation is a very important issue in 3D object detection, as it can lead to incorrect depth estimation results. HTL strategy is to train the next task after the current task is well-trained. It proposed to reduce the instability in height estimation, which occurs frequently in the early of training. As shown in Table 1, GUPNet achieved comparable performance compared to CaDDN [11], a network using a camera with LiDAR sensor.

| Methods | Type | APBEV (IoU=0.7) | AP3d (IoU=0.7) | ||||
|---|---|---|---|---|---|---|---|
| Easy | Moderate | Hard | Easy | Moderate | Hard | ||
| GUPNet [5] | Mono | 0.303 | 0.212 | 0.182 | 0.201 | 0.142 | 0.118 |
| MonoCon [6] | Mono | 0.311 | 0.221 | 0.190 | 0.225 | 0.165 | 0.140 |
| Stereo R-CNN [7] | Stereo | 0.619 | 0.413 | 0.334 | 0.476 | 0.302 | 0.237 |
| Disp R-CNN [8] | Stereo | 0.738 | 0.523 | 0.436 | 0.585 | 0.379 | 0.319 |
| CaDDN [11] | Mono & LiDAR | 0.279 | 0.189 | 0.172 | 0.192 | 0.134 | 0.115 |
| DSGN [12] | Stereo & LiDAR | 0.829 | 0.651 | 0.566 | 0.735 | 0.522 | 0.451 |
Learning Auxiliary Monocular Contexts Help Monocular 3D Object Detection (MonoCon) [2] proposed a method using only image without any extra information such as lidar, CAD model or depth estimation module. The main idea of MonoCon is to utilize well-posed 2D contexts for auxiliary learning tasks to solve ill-posed problem. As shown in Fig. 2, it generates monocular contexts about geometric information. There are four types of auxiliary contexts: 1) The heatmaps of the projected 8 corner and center points of the 3D bounding boxes, 2) The offset vectors from the center point of 2D bounding box to the projected 8 corner points of 3D bounding box, 3) The size of 2D bounding box, 4) The residual of a keypoint location. Even though it utilized simple contexts for an additional feature learning, MonoCon showed better performance than GUPNet [5].

Compared to the monocular-based detection, stereo-based can obtain richer depth information by conducting the disparity estimation using left and right images. Therefore, this method can reduce the ill-posed problem that has not been solved in the monocular method. Despite the low-priced of setting it up. It shows comparable performance compared to LiDAR-based approaches without using expensive sensor devices.
The first model to introduce is Stereo R-CNN based 3D Object Detection for Autonomous Driving (Stereo R-CNN) [7]. It is a network that simultaneously detects andassociates objects from stereo images. The algorithm is simple: First, the backbone network extracts the 2D feature from left and right images. Second, the extracted features are input into the stereo region proposal network (RPN) to concatenate them. And then, they align the proposed Region of interest (RoI) to each left-right feature map.
Finally, the aligned features are utilized to estimate the 3D bounding boxes by predicting the key-points of 3D boxes and conducting stereo regression. This approach outperformed other state-of-the-art image-based methods over 30% average precision of bird’s eye view and 3D boxes.
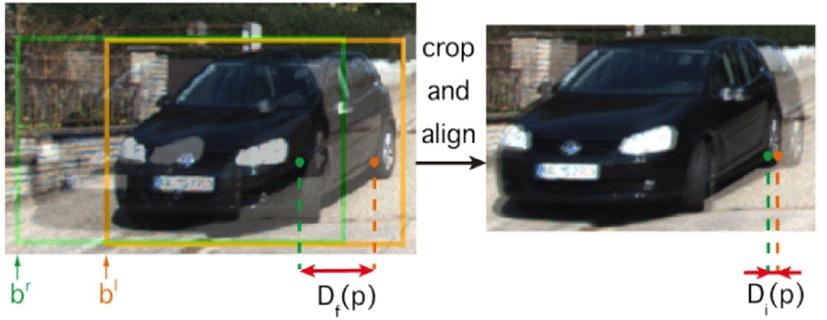
The Second is Stereo 3D Object Detection via Shape Prior Guided Instance Disparity Estimation (Disp R-CNN) [8]. Li et al. proposed a more advanced network that Stereo R-CNN [7]. The existing stereo-based 3D object detection conduct the disparity estimation of the full-frame level. However, this approach often fails to generate the accurate disparity for low textured objects like vehicle. Also, since the area of the object of interest is much smaller than the background, there are many unnecessary computations. To solve these problems, Disp R-CNN proposes object detection based on the disparity estimation of the instance level. The process of instance-level estimation is as follows: 1) specifying the object region in the feature map after RoIAlign, 2) estimating disparity of the instance-level using full-frame disparity and coordinates of the left border of left-right bounding boxes.
The instance-level disparity estimation is illustrated Fig. 3. Meanwhile, most driving datasets [16-18] do not provide ground-truth for instance disparity, so there is a problem that the disparity cannot be learned. To solve the problem, they needed to create pseudo ground-truth generation without LiDAR points. They proposed a process that uses CAD model to generate dense pseudo ground-truth. As a result, it is possible to learn the object shape prior. Disp R-CNN achieved not only state-of-the-art performance, but also faster inference time than other stereo-based models by reducing computation with novel disparity estimation.

As shown in the Table 1, Disp R-CNN performs worse than DSGN [14] which is a stereo 3D object detection method based on LiDAR. But it is better than Stereo R-CNN.
Many existing 3D Object detection used KITTI Datasets [13] as training datasets. The KITTI dataset is a collection of data with two RGB cameras, so only the Monocular and Stereo methods were possible. After that, multi-camera driving datasets such as NuScenes [17] and Waymo [18] datasets are appeared, allowing multi-view 3D object detection research.
In this task, bird’s-eye-view (BEV) representation, which is a map centered on ego-car, can be used to intuitively visualize the location, size, and orientation of the object of interest. In this paper, we introduce transformer-based approaches that recently shown excellent performance. In 2D object detection, the initial transformer-based model was DETR [19], which used object query to perform detection on the output of the decoder. The transformer-based model does not require NMS processing, and this is the same in 3D detection. Note that in multi-view detection, when feeding images into a model, do not divide the image into patches like 2D detection. They used multi-camera images as input like patches.
BEVFormer [9] generates bird’s eye view (BEV) Features that combines temporary and spatial information to perform 3D object detection and map segmentation tasks. The main components of the BEVFormer are BEV query, spatial cross attention, and temporal self-attention.
First, BEV query is a grid shaped query with the same size as BEV plane and consists of learnable parameters. Therefore, the space of the real world can be represented by BEV query. BEV query is first used in the temporal self-attention step to query temporal information from the previous BEV features. Then, BEV query is used to find spatial information through spatial cross attention between multi-view features. These output features are used as input to the feed-forward network, and as a result, the BEV feature is updated. The updated feature is used as the input of the next encoder layer.
After doing the same work on the 6 encoder layers, the BEV features BEVt at the timestamp t is completed. With that, they input to the detection head and segmentation head to predict the 3D bounding boxes and map segmentation. Finally, the BEVt is used as input for temporal self-attention at the next timestamp t-1. The temporal self-attention proposed by BEVFormer shows excellent performance of the velocity estimation than other existing camera-based method.
In Table 2, the mean average velocity error (mAVE) decreased by more than 5% compared to other camera-based models. Also, the recent camera-only methods tend to add temporal self-attention to improve the performance.
| Methods | Modality | NDS | mAP | mATE | mASE | mAOE | mAVE | mAAE |
|---|---|---|---|---|---|---|---|---|
| BEVFormer [6] | Multi-view | 0.569 | 0.481 | 0.582 | 0.256 | 0.375 | 0.378 | 0.125 |
| PETR [7] | Multi-view | 0.504 | 0.441 | 0.593 | 0.249 | 0.383 | 0.808 | 0.132 |
| Polar Former [8] | Multi-view | 0.572 | 0.493 | 0.556 | 0.256 | 0.364 | 0.440 | 0.127 |
| SSN [4] | LiDAR | 0.569 | 0.463 | - | - | - | - | - |
| CenterPoint [3] | LiDAR | 0.655 | 0.580 | - | - | - | - | - |
PETR [10] proposed a new position embedding for multi-view 3D object detection. They made a 3D coordinates generator module to represent 2D features like 3D features. It transforms the camera frustum space to the 3D world space. Meshgrid coordinates are shared by multi-view features, so the coordinates on 3D world space can be calculated by reversing the 3D projection expression with different camera parameters.
The pipeline of PETR is as follows. First, 2D feature is extracted from each view image using a backbone network such as ResNet [20] or VovNet-99 [21]. The 3D coordinate and 2D feature are then used together as inputs to the 3D position encoder to generate the 3D position-aware feature. The decoder uses these results and object query as input to predict the class and 3D bounding boxes of objects in each scene. As you can see in Fig. 5., 3D position embedding shows that the information related to position can be found well in surrounding images.

In general, 3D object detection is designed based on a Cartesian coordinate system using a perpendicular axis. PolarFormer [11] applied the polar coordinate system, noting that the real world seen in each camera from a ego-car perspective is a wedge shape. It is illustrated in Fig. 6. with the BEV map on cartesian coordinate and polar coordinate. When polar coordinate is applied, it can better represent nearby objects as in real world. Although it is difficult to implement grid shape as non-rectangular to apply polar coordinate to deep learning networks, this paper implements it in a novel way.

The pipeline of the Polar Former is as follows. First, the image of each view is fed into the backbone and FPN to extract the multi-scale 2D image feature. These feature maps are used as input to the cross-plane encoder, which converts the column of each feature into a polar ray in sequence-to-sequence format. In the polar alignment module, the generated polar relays are combined to create a polar BEV map. Then, the multi-scale BEV map is fed into the Polar BEV encoder to learn richer information across all feature scales and generate more refined BEV features. Finally, polar head utilizes multi-scale polar BEV features to predict the 3D bounding box on the Polar coordinate system and classifies the category of the object.
In Multi-view 3D object detection, features are extracted using a combination of backbone and FPN [22] to find objects of various sizes. In addition, they usually use ResNet-101 [20] and VovNet2-99 [21] and Swin-Transformer [23] as a backbone network. So far, it is difficult to detect real-time 3D object due to the large latency while extracting image features from the Backbone network. Also, it is still difficult to detect objects such as pedestrians and cyclists smaller than cars. As small object detection well in autonomous driving is important to ensure safety, research on this aspect is also required.
III. DATASETS
In this section, we will analyze two frequently used datasets in 3D object detection. KITTI dataset [14] released in 2012, and most monocular and stereo studies still widely use it. KITTI dataset uses only two RGB cameras, it can be used for the monocular method and the stereo method. Since multi-view images are not provided on the KITTI dataset, other new datasets were needed for research related to multi-view. Meanwhile, they provide point cloud information surrounding the ego-car by installing a laser scanner on the car. Although it is an old dataset, various tasks can be studied with KITTI data using various sensor modalities. In addition to object detection, they have opened several benchmarks such as flow, depth, odometry, and line detection. NuScenes dataset [17] was inspired by the KITTI dataset. To collect this dataset, they installed 6 cameras looking in various directions on the ego-car, one LiDAR, and five radars, thus providing more meta information than KITTI [14]. KITTI provides only 22 scenes, while it provides 1K scenes. In addition, KITTI has 15 k annotated frames, labeling only for 8 classes, while it is about 2.7 times more than that, and the number of classes is 23. Therefore, the nuScenes dataset is a much larger dataset in many aspects.
KITTI dataset [17] consists of 7481 training images and 7518 test images. The test dataset does not have ground-truth, so the dataset for validation is part of the training dataset. The answer label consists of three classes: Car, Cylist, and Pedestrian.
KITTI benchmark evaluates performance with average precision (AP). AP3D represents the AP of 3D bounding boxes, and APBEV represents the AP of bird's eye view. Difficulties are defined in three levels: easy, moderate, and hard. The criteria for occlusion and truncation are different depending on each level.
The nuScenes [17] dataset contains 1,000 driving scenes collected by Boston and Singapore. Each scene is about 20 seconds long, and there are 3D bounding box annotations at 2 Hz for 23 object classes. It is a driving scene taken with 6 cameras, so there are about 1.4 M camera images.
The nuScenes benchmark use 7 defined metrics. The first metric is the average precision (AP) metric considering the 2D center distance on the ground plane. And there are five true positive (TP) metrics that measure translation, scale, orientation, velocity, and attribute errors. The meanings of metric in Table 2. are as follows: Average translation error (ATE) is a metric that calculates the Euclidean center distance with a mean average translation error. Average scale Error (ASE) is a metric, which aligns the center and orientation and then calculates the 1-intersection of union (IOU) between the 3D bounding. Average orientation error (AOE) calculates the yaw angle difference between the predicted bounding box and the ground-truth bounding box. Average velocity error (AVE) calculates the difference in absolute velocity. average attribute error (AAE) is a mean average attribute error, which means the error rate of object classification. These TP metrics are calculated separately for each class, and mATE, mASE, mAOE, mAVE, and mAAE, which are calculated on average, are used in Table 2. They also use a nuScenes detection score (NDS) by computing a weighted sum of AP and TP metrics.
IV. PERFORMANCE COMPARISON
We will compare the performance of the monocular and stereo detection models in the KITTI official benchmark [16]. As shown in Table 1, the monocular 3D object detection [5-6, 11] achieved similar performance with or without LiDAR. Stereo 3D object detection using only camera [7-8] achieved slightly lower performance than the LiDAR method, DSGN [9]. However, they outperformed CaDDN [5] using a single camera and LiDAR, which shows that the using stereo cameras can learning richer semantics.
In Table 2, the performance of multi-view methods using nuScenes [17] dataset was compared. Among the models that did not use Lidar [6-8], PETR [7] achieved the lowest performance because it did not utilize temporal information for learning. As shown in Table 2, the temporal self-attention which has been first proposed by BEVFormer [6] reduced the error of velocity. Compared to SSN [4] and CenterPoint [3], which are models that utilize Point cloud together, these models achieved comparable performance.
V. CONCLUSION AND DICUSSION
In this paper, we have reviewed the monocular, stereo and multi-view 3D object detection methods. The camera-based methods still have many problems, such as incorrect 3D inference results or poor detection of small objects.
Monocular detection has a problem that geometric prior that can be obtained from one image is very insufficient. To solve these problems, modern monocular-based papers use the strategy to find contexts that can be learned in an image. Stereo-based 3D object detection often utilized disparity estimation to estimate the 3D information such as location, dimension, and orientation. Utilizing the disparity information to train the model enables more accurate detection, which means that parameters related to the camera are also important for 3D object detection. Finally, multi-view detection using the surrounding images has the advantage of being able to utilize more information such as camera parameters than monocular or stereo.
In the field of autonomous driving and robotics, most objects of interest usually move quickly. But there is a problem that all three approaches use the backbone with the large scale. This means that it is still difficult to apply to real-time detection. Therefore, efficient feature extraction will be important in future studies. In addition, there is an important problem that detection of small objects is still difficult. Enabling precise detection of small objects such as pedestrians or obstacles will also be an important issue for future research. If these problems are completely solved, image-based 3D object detection will be successful in the future, even without LiDAR system.


