
I. INTRODUCTION
Braille blocks are installed on a sidewalk to help the visually impaired person walk safely. The type of the braille block is classified into a linear type, which indicates walking in the direction of the line, and a dot type, which indicates stopping and looking around. The visually impaired person taps the braille block with a stick to acquire passage information such as the passage direction. However, it makes the walk speed of the visually impaired person slow. In addition, the obstacles on the sidewalk may be harmful to the visually impaired person waking.
Even though mounting RFID (Radio-Frequency Identi-fication) into the blocks [1-2] can be utilized for detecting the braille blocks, it is unrealistic because the existing sidewalk infrastructure should be replaced. Kuzume et al. [3] propose a detection method of the braille block through the measurement of a staff pressure change. However, it cannot solve the problem of slow walking speed. Image-based methods can detect the braille blocks quickly and accurately at a low cost through deep learning networks. Okamoto et al. [4] proposes a braille block detection method through CNN (Convolutional Neural Network) layers. The captured image is divided into 3×4 grids. It is recognized whether the blocks exist for each grid through the CNN layers. The method helps finding the braille blocks to the visually impaired person by guiding the camera capturing. Kang et al. [5] find the bounding boxes of the braille blocks through CNN layers. The shapes of the blocks are detected by binarizing the detected bounding boxes. The passage information represented by the braille blocks is recognized through the vertex detection of the block shapes.
The detections of specific objects through neural networks are widely used in various fields. The neural networks can detect various objects accurately and quickly. The passage information about the sidewalk can be recognized through the neural network by detecting braille block groups which have specific meaning. However, it is difficult to find the unlearned shape of the braille block group. In addition, it is hard to recognize a braille block group with damaged blocks by the methods. We proposed a recognition method based on the placement of the braille blocks. The braille blocks are individually detected. The meaning of the braille blocks is recognized by analyzing the placement of the braille blocks. The placement-based method can recognize the information of the braille blocks more accurately even though there are some damaged blocks.
In this paper, we propose the recognition method of the braille blocks by object-based detection. Each braille block is detected by YOLOv7 [6], which is a state-of-the-art object detection network in real time. Then, the passage information such as a walk direction and crosswalk are recognized by analyzing the placement of the detected blocks. In addition, the obstacles are also detected for the walking safety of the visually impaired person. The passage information is guided by a voice for the visually impaired person.
II. RELATED WORKS
Objects in an image can be detected through a deep learning network with CNN layers. The CNN layer performs a convolution operation with the input image and its 2D kernel. An output to be passed to the next layer is determined through its activation function. Through the CNN layer, various features in the image can be extracted while maintaining the structure of the image. After a noticeable improvement of the object detection performance through AlexNet [7] in 2012, researches on object detection through the deep learning networks have exploded.
AlexNet [7] and VGGNet [8] detect the region and class of a single object through the CNN layers. The detection accuracy increases as more CNN layers. However, deep layers in the network cause difficult network training due to a gradient vanishing that the value of error backpropagation converges to 0. ResNet [9] solves the problem to introduce a skip connection that is a shortcut between the input and output in a layer. The skip connection prevents the overfit of the network due to excessive network training. FPN [10] can detect the object with various sizes through multiple resolution sampling layers. SSFPN [11] utilizes scaleinvariant features which are extracted by 3D CNN. Multiscale objects can also be detected by a super resolution method [12].
It is very difficult to design networks with outputs for detection results about multiple objects because the number of objects to recognize is variable. Instead, the networks divide the input image before the object detection to detect the single object for each divided region. The networks for the multiple objects are classified into two types based on the image segmentation method. One of them obtains the regions by region proposal, which divides the image based on colors, textures, or feature vectors in order that each region has a single object with high probability. It is called a 2-stage detector because the object detection is performed in a region proposal stage and a detection stage. The other network divides the image into regions of equal size rectangles. The network needs only one stage, so then this network is called a 1-stage detector. The detection accuracy of the 1-stage detector is faster than the 2-stage detector due to the region proposal stage in the 2-stage detector. On the other hand, the 2-stage de-tector is better for the accuracy of the object detection.
R-CNN [13] is an early detector for multiple objects. R-CNN detects the multiple objects through 2-stage, that is the region proposal and the object detection. However, the CNN is applied to only extract the features of the image, while the region proposal and the object detection are not performed through the network. Therefore, the detection speed is very slow. Fast R-CNN [14] and Faster R-CNN [15] improve the detection speed by introducing networks for the object detection and for the region proposal, respectively. Unlike the R-CNN families, YOLO families and SSD are a 1-stage detector. YOLO [16] divides the image into regions of equal size and performs object detection on each region. YOLO does not require the region proposal, so the detection speed is faster than the 2-stage detectors such as Faster R-CNN. YOLO has been revised to improve the detection accuracy and processing time [6, 17-18]. SSD [19] utilizes the features from image scaled to various sizes by a pyramidal feature hierarchy to detect the multiscaled objects.
III. BRAILLE BLOCK GUIDANCE FOR VISUALLY IMPAIRED PERSON
The braille blocks are classified into the following three types: a straight block in front direction, a straight block in side direction, and a dot block. Fig. 1 shows the types of the braille block.

YOLOv7 [6] is a network for detecting the braille blocks. YOLOv7 can detect multiobjects in real time. We train the detection network through the images of sidewalks including the braille blocks in AI HUB [20]. The braille blocks in the training images are labeled and are trained into YOLO. Obstacle objects such as scooters and bicycles in the images are also trained in order to warn them on the sidewalk during walking. The number of the images for the network training is 200. The training images have about 1,635 braille blocks and 48 obstacle objects. 80% of the training images are utilized for the network training and the others validate the training. In the network training, the number of epochs and the learning rate are 500 and 1×10−3, respectively, and an input image size is 640×640. Fig. 2 shows the samples of the images for network training.

Fig. 3 shows the detection results. The braille blocks and the obstacles are detected well for each object.

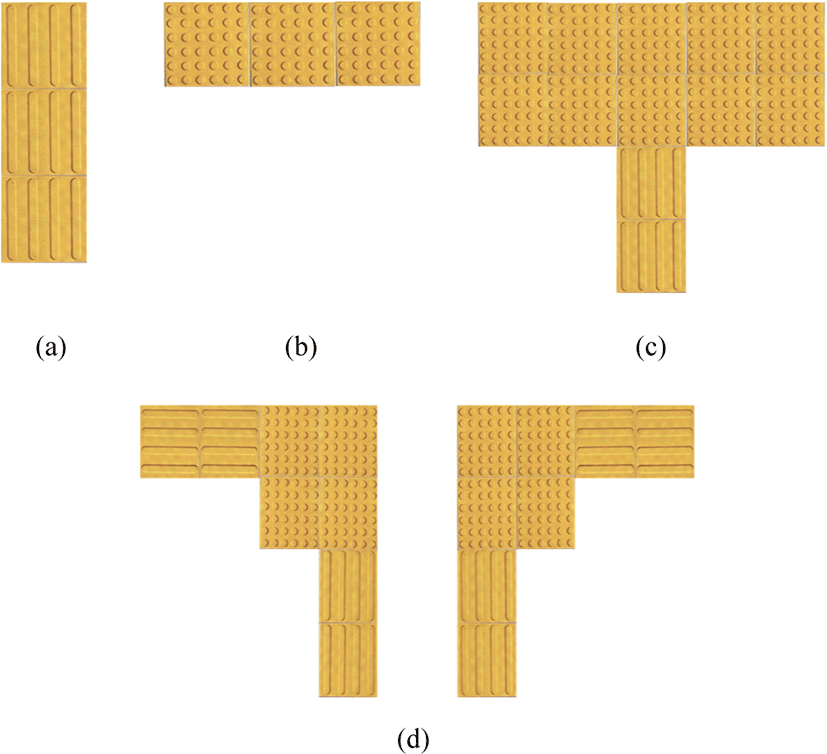
In order to provide the passage information of the sidewalk for the visually impaired person, the braille blocks, whose types are the dot and the straight, are placed in special shapes. The passage information according to the placement of the braille blocks are as follows: three or more consecutive straight blocks is a straight section; a set of the consecutive dot blocks is a stop section; a placement of the dot blocks in two lines horizontally after the consecutive straight blocks vertically means that the crosswalk is in front; a placement of sets of horizontal and vertical straight blocks at right angles is a turn section. Fig. 4 shows the passage information according to the placement of the braille blocks.
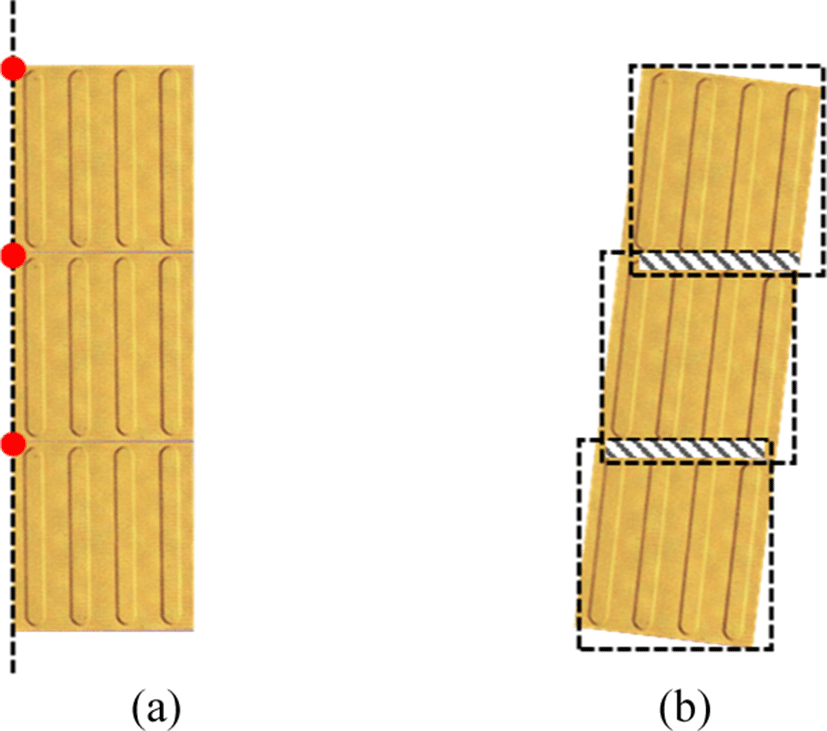
A straight section is recognized by finding 5 or more straight blocks in a single line. Consecutive blocks arranged in a single line have the same x coordinate or the same y coordinate of their topleft points if the capture and the movement directions are equal. If the image is tilted, the coordinates are not equal. However, the bounding boxes of the blocks overlap as shown in Fig. 5(b). Therefore, the straight section can be recognized by detecting 5 or more overlapping bounding boxes of the straight blocks in a vertical direction. The stop section is recognized by detecting 3 or more overlapping bounding boxes of the dot blocks in a horizontal direction. The crosswalk section is recognized by detecting dot blocks in double lines, that is by detecting 5 or more bounding boxes of the braille blocks overlapping in both of the vertical and the horizontal directions. The turn section is recognized by detecting the overlapping bounding boxes between the dot and the straight blocks in a horizontal direction and a vertical direction as shown in Fig. 6. The turn direction is right in case that the maximum x coordinate among the bottomright points of the straight blocks is larger than the maximum coordinate among the dot blocks.

In order to guide the passage information for the visually impaired person by detecting the braille block, images are captured through a camera mounted on a smartphone that the people always have. The captured image is transmitted to a server device having high-performance computing power for the real-time detection. The recognized passage information is guided by voice for the visually impaired person after receiving the recognition result from the server. If the obstacles are detected, the warning information about the obstacles is guided preferentially over the passage information. Fig. 7 shows the voice guidance of the passage information about the sidewalk.

The passage information may be very early guided due to far braille blocks. For the guidance at a right time, the regions of a 1/5 height at top and bottom of the captured image are not used to recognition, respectively as shown in Fig. 8.

IV. SIMULATION RESULTS
The accuracies of the braille block detection and the passage information recognition are measured. We capture the sidewalk including the braille blocks which indicate the sections of only straight, of only turn, of combined turn and straight, of a crossroad, and of a crosswalk. Similar to actual capture situations for the sidewalk, the sidewalk videos for the simulation are captured with 25 degrees, 30 degrees, and 35 degrees angles relative to the ground as shown in Fig. 9. First 60 frames of the captured videos are utilized for the simulations. Table 1 shows the number of the simulation videos for the cases.

Table 2 shows the accuracy of the braille block detection. The braille blocks are almost accurately detected in case of the videos with the low capture angles. As the capture angle is larger, the far blocks are sometimes not detected or their types are incorrectly detected.
| Capture angles | No. blocks | Correct detection | False detection | Not detected |
|---|---|---|---|---|
| 25° | 431 | 414 | 15 | 2 |
| 30° | 532 | 505 | 22 | 5 |
| 35° | 641 | 588 | 38 | 15 |
The accuracy of the passage information recognition is shown in Table 3. The passage direction is almost recognized accurately for 25 degrees of the capture angle. When the capture angle is 30 or 35 degrees, the straight and crosswalk sections are well detected, but the recognition of the turn sections are sometimes wrong.
Table 4 shows the result of the obstacle object detection. The obstacle objects are accurately detected. However, the unlearned object cannot be detected. In order to solve this problem, more various types of obstacle objects need to be trained in the network.
| Number of obstacles | Correct detection | Not detected |
|---|---|---|
| 43 | 39 | 4 |
V. CONCLUSION
In this paper, we proposed the recognition method of the passage information about the sidewalk by detecting the braille block through deep learning. The braille blocks and the obstacles were individually detected by YOLOv7. The passage information about the sidewalk was recognized by analyzing the placement of the braille blocks. Either the passage information or the warning information about the obstacles was guided by voice for the visually impaired person. In the simulation results, the accuracy of the passage information recognition was about 85%. The proposed method may be helped for not only the guidance for the visually impaired person but also autonomous driving of robots on the sidewalk.
 received the B.S., M.S., and Ph.D. degrees in Computer Software Engineering from Dongeui University in 2015, 2017, and 2021, respectively, and is currently a research professor in AI Grand ICT Research Center at Dongeui University. His research interest is in the areas of image processing and video processing.
received the B.S., M.S., and Ph.D. degrees in Computer Software Engineering from Dongeui University in 2015, 2017, and 2021, respectively, and is currently a research professor in AI Grand ICT Research Center at Dongeui University. His research interest is in the areas of image processing and video processing. is currently an undergraduate student in the Department of Computer Software Engineering at Dongeui University. His research interest is in the areas of image recognition.
is currently an undergraduate student in the Department of Computer Software Engineering at Dongeui University. His research interest is in the areas of image recognition. received the B.S. degree in Electronic Engineering from Kyungpook National University, in 1990, the M.S. and Ph.D. degrees in Electrical Engineering from Korea Advanced Institute of Science and Technology (KAIST), in 1992 and 1998, respectively. From 1998 to 2000, he was a team manager at Technology Appraisal Center of Korea Technology Guarantee Fund. Since 2001, he has been a faculty member of Dongeui University, where he is now a professor in the Department of Computer Software Engineering. From 2003 to 2004, he was a visiting professor of the Department of Electrical Engineering in the University of Texas at Arlington. From 2010 to 2011, he was an international visiting research associate in the School of Engineering and Advanced Technology in Massey University. Prof. Kwon received the awards, Leading Engineers of the World 2008 and Foremost Engineers of the World 2008, from IBC, and best papers from Korea Multimedia Society, respectively. His biographical profile has been included in the 2008~2014, 2017~2019 Editions of Marquis Who’s Who in the World and the 2009/2010 Edition of IBC Outstanding 2000 Intellectuals of the 21st Century. He is an associate editor for IEICE Nolta journal, a topic editor for MDPI Electronics journal, and a reviewer board member for MDPI Signals journal. Also he is working as a reviewer for several journals such as Sensors, Applied Sciences, Information, Symmetry, Entropy, IEEE TCSVT, and IEEE Access. His research interests are in the areas of image processing, video processing, video transmission, depth data processing, and AI object recognition.
received the B.S. degree in Electronic Engineering from Kyungpook National University, in 1990, the M.S. and Ph.D. degrees in Electrical Engineering from Korea Advanced Institute of Science and Technology (KAIST), in 1992 and 1998, respectively. From 1998 to 2000, he was a team manager at Technology Appraisal Center of Korea Technology Guarantee Fund. Since 2001, he has been a faculty member of Dongeui University, where he is now a professor in the Department of Computer Software Engineering. From 2003 to 2004, he was a visiting professor of the Department of Electrical Engineering in the University of Texas at Arlington. From 2010 to 2011, he was an international visiting research associate in the School of Engineering and Advanced Technology in Massey University. Prof. Kwon received the awards, Leading Engineers of the World 2008 and Foremost Engineers of the World 2008, from IBC, and best papers from Korea Multimedia Society, respectively. His biographical profile has been included in the 2008~2014, 2017~2019 Editions of Marquis Who’s Who in the World and the 2009/2010 Edition of IBC Outstanding 2000 Intellectuals of the 21st Century. He is an associate editor for IEICE Nolta journal, a topic editor for MDPI Electronics journal, and a reviewer board member for MDPI Signals journal. Also he is working as a reviewer for several journals such as Sensors, Applied Sciences, Information, Symmetry, Entropy, IEEE TCSVT, and IEEE Access. His research interests are in the areas of image processing, video processing, video transmission, depth data processing, and AI object recognition.